commit
8d80c6b1e1
17 changed files with 2044 additions and 1542 deletions
|
|
@ -19,7 +19,7 @@ WORKDIR /app
|
|||
|
||||
# run crond as main process of container
|
||||
ENTRYPOINT ["/bin/sh", "/app/entrypoint.sh"]
|
||||
CMD ["dishStatusInflux.py"]
|
||||
CMD ["dish_grpc_influx.py status alert_detail"]
|
||||
|
||||
# docker run -d --name='starlink-grpc-tools' -e INFLUXDB_HOST=192.168.1.34 -e INFLUXDB_PORT=8086 -e INFLUXDB_DB=starlink
|
||||
# --net='br0' --ip='192.168.1.39' neurocis/starlink-grpc-tools dishStatusInflux.py
|
||||
# --net='br0' --ip='192.168.1.39' neurocis/starlink-grpc-tools dish_grpc_influx.py status alert_detail
|
||||
|
|
|
|||
46
README.md
46
README.md
|
|
@ -38,7 +38,7 @@ python parseJsonHistory.py -h
|
|||
|
||||
When used as-is, `parseJsonHistory.py` will summarize packet loss information from the data the dish records. There's other bits of data in there, though, so that script (or more likely the parsing logic it uses, which now resides in `starlink_json.py`) could be used as a starting point or example of how to iterate through it. Most of the data displayed in the Statistics page of the Starlink app appears to come from this same `get_history` gRPC response. See the file `get_history_notes.txt` for some ramblings on how to interpret it.
|
||||
|
||||
The one bit of functionality this script has over the grpc scripts is that it supports capturing the grpcurl output to a file and reading from that, which may be useful if you're collecting data in one place but analyzing it in another. Otherwise, it's probably better to use `dishHistoryStats.py`, described below.
|
||||
The one bit of functionality this script has over the grpc scripts is that it supports capturing the grpcurl output to a file and reading from that, which may be useful if you're collecting data in one place but analyzing it in another. Otherwise, it's probably better to use `dish_grpc_text.py`, described below.
|
||||
|
||||
### The grpc scripts
|
||||
|
||||
|
|
@ -57,52 +57,60 @@ python3 -m grpc_tools.protoc --descriptor_set_in=../dish.protoset --python_out=.
|
|||
```
|
||||
Then move the resulting files to where the Python scripts can find them in the import path, such as in the same directory as the scripts themselves.
|
||||
|
||||
Once those are available, the `dishHistoryStats.py` script can be used in place of the `grpcurl | parseJsonHistory.py` pipeline, with most of the same command line options. For example:
|
||||
Once those are available, the `dish_grpc_text.py` script can be used in place of the `grpcurl | parseJsonHistory.py` pipeline; however, the command line interface is slightly different because `dish_grpc_text.py` supports additional functionality. The equivalent command to `grpcurl | parseJsonHistory.py` would be:
|
||||
```
|
||||
python3 parseHistoryStats.py
|
||||
python3 dish_grpc_text.py ping_drop
|
||||
```
|
||||
|
||||
By default, `parseHistoryStats.py` (and `parseJsonHistory.py`) will output the stats in CSV format. You can use the `-v` option to instead output in a (slightly) more human-readable format.
|
||||
By default, `dish_grpc_text.py` (and `parseJsonHistory.py`) will output in CSV format. You can use the `-v` option to instead output in a (slightly) more human-readable format.
|
||||
|
||||
To collect and record summary stats at the top of every hour, you could put something like the following in your user crontab (assuming you have moved the scripts to ~/bin and made them executable):
|
||||
To collect and record packet loss summary stats at the top of every hour, you could put something like the following in your user crontab (assuming you have moved the scripts to ~/bin and made them executable):
|
||||
```
|
||||
00 * * * * [ -e ~/dishStats.csv ] || ~/bin/dishHistoryStats.py -H >~/dishStats.csv; ~/bin/dishHistoryStats.py >>~/dishStats.csv
|
||||
00 * * * * [ -e ~/dishStats.csv ] || ~/bin/dish_grpc_text.py -H >~/dishStats.csv; ~/bin/dish_grpc_text.py ping_drop >>~/dishStats.csv
|
||||
```
|
||||
|
||||
`dishHistoryInflux.py` and `dishHistoryMqtt.py` are similar, but they send their output to an InfluxDB server and a MQTT broker, respectively. Run them with `-h` command line option for details on how to specify server and/or database options.
|
||||
`dish_grpc_influx.py`, `dish_grpc_sqlite.py`, and `dish_grpc_mqtt.py` are similar, but they send their output to an InfluxDB server, a sqlite database, and a MQTT broker, respectively. Run them with `-h` command line option for details on how to specify server and/or database options.
|
||||
|
||||
`dishStatusCsv.py`, `dishStatusInflux.py`, and `dishStatusMqtt.py` output the status data instead of history data, to various data backends. The information they pull is mostly what appears related to the dish in the Debug Data section of the Starlink app. As with the corresponding history scripts, run them with `-h` command line option for usage details.
|
||||
All 4 scripts support processing status data in addition to the history data. The status data is mostly what appears related to the dish in the Debug Data section of the Starlink app. Specific status or history data groups can be selected by including their mode names on the command line. Run the scripts with `-h` command line option to get a list of available modes. See the documentation at the top of `starlink_grpc.py` for detail on what each of the fields means within each mode group.
|
||||
|
||||
By default, all of these scripts will pull data once, send it off to the specified data backend, and then exit. They can instead be made to run in a periodic loop by passing a `-t` option to specify loop interval, in seconds. For example, to capture status information to a InfluxDB server every 30 seconds, you could do something like this:
|
||||
```
|
||||
python3 dishStatusInflux.py -t 30 [... probably other args to specify server options ...]
|
||||
python3 dish_grpc_influx.py -t 30 [... probably other args to specify server options ...] status
|
||||
```
|
||||
|
||||
Some of the scripts (currently only the InfluxDB ones) also support specifying options through environment variables. See details in the scripts for the environment variables that map to options.
|
||||
Some of the scripts (currently only the InfluxDB one) also support specifying options through environment variables. See details in the scripts for the environment variables that map to options.
|
||||
|
||||
#### Bulk history data collection
|
||||
|
||||
`dishStatusInflux.py` also supports a bulk mode that collects and writes the full second-by-second data to the server instead of summary stats. To select bulk mode, use the `-b` option. You'll probably also want to use the `-t` option to have it run in a loop.
|
||||
`dish_grpc_influx.py`, `dish_grpc_sqlite.py`, and `dish_grpc_text.py` also support a bulk history mode that collects and writes the full second-by-second data instead of summary stats. To select bulk mode, use `bulk_history` for the mode argument. You'll probably also want to use the `-t` option to have it run in a loop.
|
||||
|
||||
### Other scripts
|
||||
|
||||
`dishDumpStatus.py` is a simple example of how to use the grpc modules (the ones generated by protoc, not `starlink_grpc.py`) directly. Just run it as:
|
||||
`dump_dish_status.py` is a simple example of how to use the grpc modules (the ones generated by protoc, not `starlink_grpc`) directly. Just run it as:
|
||||
```
|
||||
python3 dishDumpStatus.py
|
||||
python3 dump_dish_status.py
|
||||
```
|
||||
and revel in copious amounts of dish status information. OK, maybe it's not as impressive as all that. This one is really just meant to be a starting point for real functionality to be added to it.
|
||||
|
||||
`poll_history.py` is another silly example, but this one illustrates how to periodically poll the status and/or bulk history data using the `starlink_grpc` module's API. It's not really useful by itself, but if you really want to, you can run it as:
|
||||
```
|
||||
python3 poll_history.py
|
||||
```
|
||||
Possibly more simple examples to come, as the other scripts have started getting a bit complicated.
|
||||
|
||||
## To Be Done (Maybe)
|
||||
|
||||
Maybe more data backend options. If there's one you'd like to see supported, please open a feature request issue.
|
||||
|
||||
There are `reboot` and `dish_stow` requests in the Device protocol, too, so it should be trivial to write a command that initiates dish reboot and stow operations. These are easy enough to do with `grpcurl`, though, as there is no need to parse through the response data. For that matter, they're easy enough to do with the Starlink app.
|
||||
|
||||
Proper Python packaging, since some of the scripts are no longer self-contained.
|
||||
|
||||
The requirement to run `grpcurl` and `protoc` could be eliminated by adding support for use of gRPC server reflection directly in the grpc scripts. This would sidestep any packaging questions about whether or not the protoc-generated files could be redistributed.
|
||||
|
||||
## Other Tidbits
|
||||
|
||||
The Starlink Android app actually uses port 9201 instead of 9200. Both appear to expose the same gRPC service, but the one on port 9201 uses an HTTP/1.1 wrapper, whereas the one on port 9200 uses HTTP/2.0, which is what most gRPC tools expect.
|
||||
The Starlink Android app actually uses port 9201 instead of 9200. Both appear to expose the same gRPC service, but the one on port 9201 uses [gRPC-Web](https://github.com/grpc/grpc/blob/master/doc/PROTOCOL-WEB.md), which can use HTTP/1.1, whereas the one on port 9200 uses HTTP/2, which is what most gRPC tools expect.
|
||||
|
||||
The Starlink router also exposes a gRPC service, on ports 9000 (HTTP/2.0) and 9001 (HTTP/1.1).
|
||||
|
||||
|
|
@ -116,13 +124,17 @@ docker run -d -t --name='starlink-grpc-tools' -e INFLUXDB_HOST={InfluxDB Hostnam
|
|||
-e INFLUXDB_USER={Optional, InfluxDB Username} \
|
||||
-e INFLUXDB_PWD={Optional, InfluxDB Password} \
|
||||
-e INFLUXDB_DB={Pre-created DB name, starlinkstats works well} \
|
||||
neurocis/starlink-grpc-tools dishStatusInflux.py -v
|
||||
neurocis/starlink-grpc-tools dish_grpc_influx.py -v status alert_detail
|
||||
```
|
||||
|
||||
The `-t` option to `docker run` will prevent Python from buffering the script's standard output and can be omitted if you don't care about seeing the verbose output in the container logs as soon as it is printed.
|
||||
|
||||
The `dishStatusInflux.py -v` is optional and omitting it will run same but not verbose, or you can replace it with one of the other scripts if you wish to run that instead, or use other command line options. There is also a `GrafanaDashboard - Starlink Statistics.json` which can be imported to get some charts like:
|
||||
The `dish_grpc_influx.py -v status alert_detail` is optional and omitting it will run same but not verbose, or you can replace it with one of the other scripts if you wish to run that instead, or use other command line options. There is also a `GrafanaDashboard - Starlink Statistics.json` which can be imported to get some charts like:
|
||||
|
||||
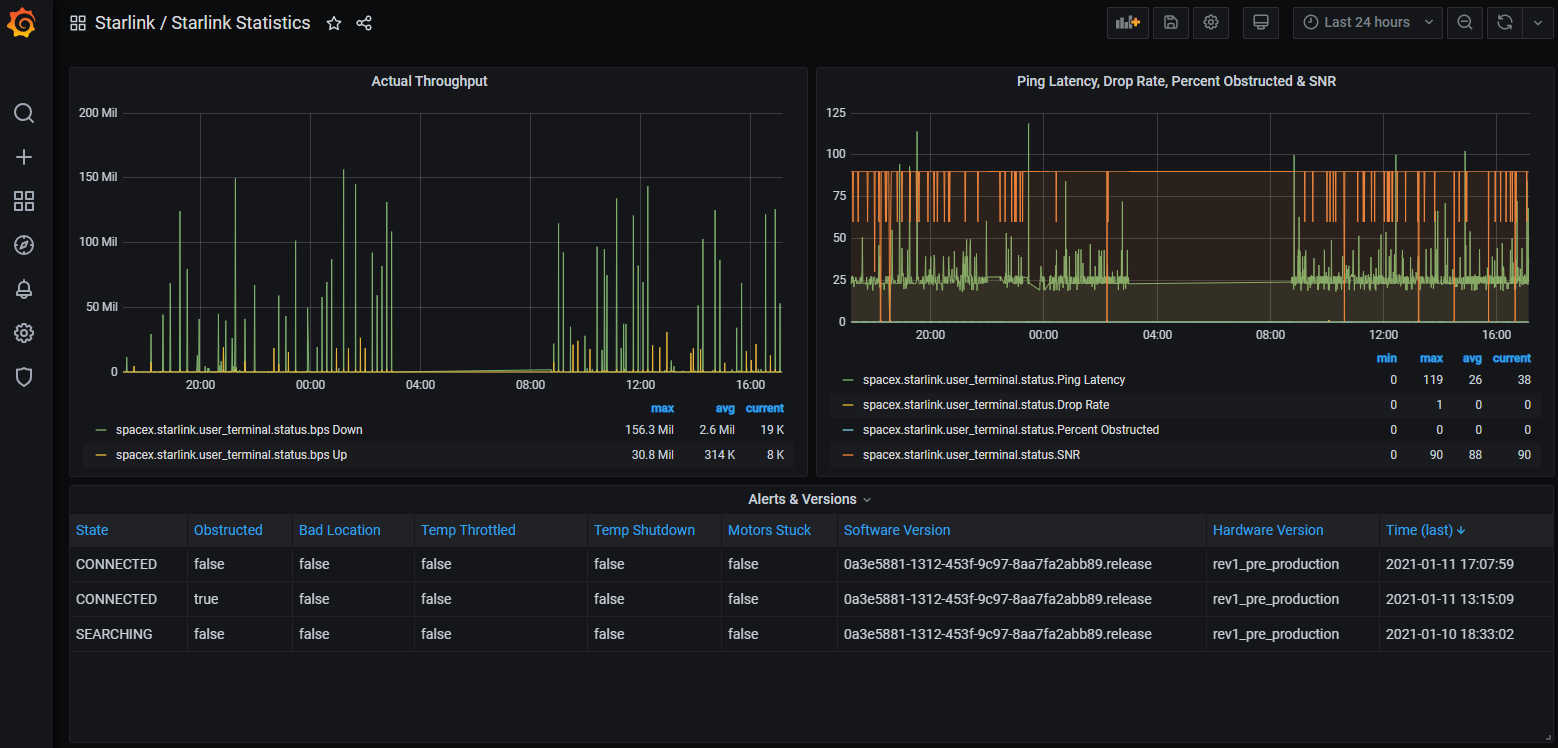
|
||||
|
||||
You'll probably want to run with the `-t` option to `dishStatusInflux.py` to collect status information periodically for this to be meaningful.
|
||||
You'll probably want to run with the `-t` option to `dish_grpc_influx.py` to collect status information periodically for this to be meaningful.
|
||||
|
||||
## Related Projects
|
||||
|
||||
[ChuckTSI's Better Than Nothing Web Interface](https://github.com/ChuckTSI/BetterThanNothingWebInterface) uses grpcurl and PHP to provide a spiffy web UI for some of the same data this project works on.
|
||||
|
|
|
|||
|
|
@ -1,26 +0,0 @@
|
|||
#!/usr/bin/python3
|
||||
######################################################################
|
||||
#
|
||||
# Simple example of how to poll the get_status request directly using
|
||||
# grpc calls.
|
||||
#
|
||||
######################################################################
|
||||
import grpc
|
||||
|
||||
import spacex.api.device.device_pb2
|
||||
import spacex.api.device.device_pb2_grpc
|
||||
|
||||
# Note that if you remove the 'with' clause here, you need to separately
|
||||
# call channel.close() when you're done with the gRPC connection.
|
||||
with grpc.insecure_channel("192.168.100.1:9200") as channel:
|
||||
stub = spacex.api.device.device_pb2_grpc.DeviceStub(channel)
|
||||
response = stub.Handle(spacex.api.device.device_pb2.Request(get_status={}))
|
||||
|
||||
# Dump everything
|
||||
print(response)
|
||||
|
||||
## Just the software version
|
||||
#print(response.dish_get_status.device_info.software_version)
|
||||
|
||||
## Check if connected
|
||||
#print("Connected" if response.dish_get_status.state == spacex.api.device.dish_pb2.DishState.CONNECTED else "Not connected")
|
||||
|
|
@ -1,414 +0,0 @@
|
|||
#!/usr/bin/python3
|
||||
######################################################################
|
||||
#
|
||||
# Write Starlink user terminal packet loss, latency, and usage data
|
||||
# to an InfluxDB database.
|
||||
#
|
||||
# This script examines the most recent samples from the history data,
|
||||
# and either writes them in whole, or computes several different
|
||||
# metrics related to packet loss and writes those, to the specified
|
||||
# InfluxDB database.
|
||||
#
|
||||
# NOTE: The Starlink user terminal does not include time values with
|
||||
# its history or status data, so this script uses current system time
|
||||
# to compute the timestamps it sends to InfluxDB. It is recommended
|
||||
# to run this script on a host that has its system clock synced via
|
||||
# NTP. Otherwise, the timestamps may get out of sync with real time.
|
||||
#
|
||||
######################################################################
|
||||
|
||||
import getopt
|
||||
from datetime import datetime
|
||||
from datetime import timezone
|
||||
import logging
|
||||
import os
|
||||
import signal
|
||||
import sys
|
||||
import time
|
||||
import warnings
|
||||
|
||||
from influxdb import InfluxDBClient
|
||||
|
||||
import starlink_grpc
|
||||
|
||||
BULK_MEASUREMENT = "spacex.starlink.user_terminal.history"
|
||||
PING_MEASUREMENT = "spacex.starlink.user_terminal.ping_stats"
|
||||
MAX_QUEUE_LENGTH = 864000
|
||||
|
||||
|
||||
class Terminated(Exception):
|
||||
pass
|
||||
|
||||
|
||||
def handle_sigterm(signum, frame):
|
||||
# Turn SIGTERM into an exception so main loop can clean up
|
||||
raise Terminated()
|
||||
|
||||
|
||||
def main():
|
||||
arg_error = False
|
||||
|
||||
try:
|
||||
opts, args = getopt.getopt(sys.argv[1:], "abhkn:p:rs:t:vC:D:IP:R:SU:")
|
||||
except getopt.GetoptError as err:
|
||||
print(str(err))
|
||||
arg_error = True
|
||||
|
||||
# Default to 1 hour worth of data samples.
|
||||
samples_default = 3600
|
||||
samples = None
|
||||
print_usage = False
|
||||
verbose = False
|
||||
default_loop_time = 0
|
||||
loop_time = default_loop_time
|
||||
bulk_mode = False
|
||||
bulk_skip_query = False
|
||||
run_lengths = False
|
||||
host_default = "localhost"
|
||||
database_default = "starlinkstats"
|
||||
icargs = {"host": host_default, "timeout": 5, "database": database_default}
|
||||
rp = None
|
||||
flush_limit = 6
|
||||
max_batch = 5000
|
||||
|
||||
# For each of these check they are both set and not empty string
|
||||
influxdb_host = os.environ.get("INFLUXDB_HOST")
|
||||
if influxdb_host:
|
||||
icargs["host"] = influxdb_host
|
||||
influxdb_port = os.environ.get("INFLUXDB_PORT")
|
||||
if influxdb_port:
|
||||
icargs["port"] = int(influxdb_port)
|
||||
influxdb_user = os.environ.get("INFLUXDB_USER")
|
||||
if influxdb_user:
|
||||
icargs["username"] = influxdb_user
|
||||
influxdb_pwd = os.environ.get("INFLUXDB_PWD")
|
||||
if influxdb_pwd:
|
||||
icargs["password"] = influxdb_pwd
|
||||
influxdb_db = os.environ.get("INFLUXDB_DB")
|
||||
if influxdb_db:
|
||||
icargs["database"] = influxdb_db
|
||||
influxdb_rp = os.environ.get("INFLUXDB_RP")
|
||||
if influxdb_rp:
|
||||
rp = influxdb_rp
|
||||
influxdb_ssl = os.environ.get("INFLUXDB_SSL")
|
||||
if influxdb_ssl:
|
||||
icargs["ssl"] = True
|
||||
if influxdb_ssl.lower() == "secure":
|
||||
icargs["verify_ssl"] = True
|
||||
elif influxdb_ssl.lower() == "insecure":
|
||||
icargs["verify_ssl"] = False
|
||||
else:
|
||||
icargs["verify_ssl"] = influxdb_ssl
|
||||
|
||||
if not arg_error:
|
||||
if len(args) > 0:
|
||||
arg_error = True
|
||||
else:
|
||||
for opt, arg in opts:
|
||||
if opt == "-a":
|
||||
samples = -1
|
||||
elif opt == "-b":
|
||||
bulk_mode = True
|
||||
elif opt == "-h":
|
||||
print_usage = True
|
||||
elif opt == "-k":
|
||||
bulk_skip_query = True
|
||||
elif opt == "-n":
|
||||
icargs["host"] = arg
|
||||
elif opt == "-p":
|
||||
icargs["port"] = int(arg)
|
||||
elif opt == "-r":
|
||||
run_lengths = True
|
||||
elif opt == "-s":
|
||||
samples = int(arg)
|
||||
elif opt == "-t":
|
||||
loop_time = float(arg)
|
||||
elif opt == "-v":
|
||||
verbose = True
|
||||
elif opt == "-C":
|
||||
icargs["ssl"] = True
|
||||
icargs["verify_ssl"] = arg
|
||||
elif opt == "-D":
|
||||
icargs["database"] = arg
|
||||
elif opt == "-I":
|
||||
icargs["ssl"] = True
|
||||
icargs["verify_ssl"] = False
|
||||
elif opt == "-P":
|
||||
icargs["password"] = arg
|
||||
elif opt == "-R":
|
||||
rp = arg
|
||||
elif opt == "-S":
|
||||
icargs["ssl"] = True
|
||||
icargs["verify_ssl"] = True
|
||||
elif opt == "-U":
|
||||
icargs["username"] = arg
|
||||
|
||||
if "password" in icargs and "username" not in icargs:
|
||||
print("Password authentication requires username to be set")
|
||||
arg_error = True
|
||||
|
||||
if print_usage or arg_error:
|
||||
print("Usage: " + sys.argv[0] + " [options...]")
|
||||
print("Options:")
|
||||
print(" -a: Parse all valid samples")
|
||||
print(" -b: Bulk mode: write individual sample data instead of summary stats")
|
||||
print(" -h: Be helpful")
|
||||
print(" -k: Skip querying for prior sample write point in bulk mode")
|
||||
print(" -n <name>: Hostname of InfluxDB server, default: " + host_default)
|
||||
print(" -p <num>: Port number to use on InfluxDB server")
|
||||
print(" -r: Include ping drop run length stats")
|
||||
print(" -s <num>: Number of data samples to parse; in bulk mode, applies to first")
|
||||
print(" loop iteration only, default: -1 in bulk mode, loop interval if")
|
||||
print(" loop interval set, else " + str(samples_default))
|
||||
print(" -t <num>: Loop interval in seconds or 0 for no loop, default: " +
|
||||
str(default_loop_time))
|
||||
print(" -v: Be verbose")
|
||||
print(" -C <filename>: Enable SSL/TLS using specified CA cert to verify server")
|
||||
print(" -D <name>: Database name to use, default: " + database_default)
|
||||
print(" -I: Enable SSL/TLS but disable certificate verification (INSECURE!)")
|
||||
print(" -P <word>: Set password for authentication")
|
||||
print(" -R <name>: Retention policy name to use")
|
||||
print(" -S: Enable SSL/TLS using default CA cert")
|
||||
print(" -U <name>: Set username for authentication")
|
||||
sys.exit(1 if arg_error else 0)
|
||||
|
||||
if samples is None:
|
||||
samples = -1 if bulk_mode else int(loop_time) if loop_time > 0 else samples_default
|
||||
|
||||
logging.basicConfig(format="%(levelname)s: %(message)s")
|
||||
|
||||
class GlobalState:
|
||||
pass
|
||||
|
||||
gstate = GlobalState()
|
||||
gstate.dish_id = None
|
||||
gstate.points = []
|
||||
gstate.counter = None
|
||||
gstate.timestamp = None
|
||||
gstate.query_done = bulk_skip_query
|
||||
|
||||
def conn_error(msg, *args):
|
||||
# Connection errors that happen in an interval loop are not critical
|
||||
# failures, but are interesting enough to print in non-verbose mode.
|
||||
if loop_time > 0:
|
||||
print(msg % args)
|
||||
else:
|
||||
logging.error(msg, *args)
|
||||
|
||||
def flush_points(client):
|
||||
# Don't flush points to server if the counter query failed, since some
|
||||
# may be discarded later. Write would probably fail, too, anyway.
|
||||
if bulk_mode and not gstate.query_done:
|
||||
return 1
|
||||
|
||||
try:
|
||||
while len(gstate.points) > max_batch:
|
||||
client.write_points(gstate.points[:max_batch],
|
||||
time_precision="s",
|
||||
retention_policy=rp)
|
||||
if verbose:
|
||||
print("Data points written: " + str(max_batch))
|
||||
del gstate.points[:max_batch]
|
||||
if gstate.points:
|
||||
client.write_points(gstate.points, time_precision="s", retention_policy=rp)
|
||||
if verbose:
|
||||
print("Data points written: " + str(len(gstate.points)))
|
||||
gstate.points.clear()
|
||||
except Exception as e:
|
||||
conn_error("Failed writing to InfluxDB database: %s", str(e))
|
||||
# If failures persist, don't just use infinite memory. Max queue
|
||||
# is currently 10 days of bulk data, so something is very wrong
|
||||
# if it's ever exceeded.
|
||||
if len(gstate.points) > MAX_QUEUE_LENGTH:
|
||||
logging.error("Max write queue exceeded, discarding data.")
|
||||
del gstate.points[:-MAX_QUEUE_LENGTH]
|
||||
return 1
|
||||
|
||||
return 0
|
||||
|
||||
def query_counter(client, now, len_points):
|
||||
try:
|
||||
# fetch the latest point where counter field was recorded
|
||||
result = client.query("SELECT counter FROM \"{0}\" "
|
||||
"WHERE time>={1}s AND time<{2}s AND id=$id "
|
||||
"ORDER by time DESC LIMIT 1;".format(
|
||||
BULK_MEASUREMENT, now - len_points, now),
|
||||
bind_params={"id": gstate.dish_id},
|
||||
epoch="s")
|
||||
rpoints = list(result.get_points())
|
||||
if rpoints:
|
||||
counter = rpoints[0].get("counter", None)
|
||||
timestamp = rpoints[0].get("time", 0)
|
||||
if counter and timestamp:
|
||||
return int(counter), int(timestamp)
|
||||
except TypeError as e:
|
||||
# bind_params was added in influxdb-python v5.2.3. That would be
|
||||
# easy enough to work around, but older versions had other problems
|
||||
# with query(), so just skip this functionality.
|
||||
logging.error(
|
||||
"Failed running query, probably due to influxdb-python version too old. "
|
||||
"Skipping resumption from prior counter value. Reported error was: %s", str(e))
|
||||
|
||||
return None, 0
|
||||
|
||||
def process_bulk_data(client):
|
||||
before = time.time()
|
||||
|
||||
start = gstate.counter
|
||||
parse_samples = samples if start is None else -1
|
||||
general, bulk = starlink_grpc.history_bulk_data(parse_samples, start=start, verbose=verbose)
|
||||
|
||||
after = time.time()
|
||||
parsed_samples = general["samples"]
|
||||
new_counter = general["end_counter"]
|
||||
timestamp = gstate.timestamp
|
||||
# check this first, so it doesn't report as lost time sync
|
||||
if gstate.counter is not None and new_counter != gstate.counter + parsed_samples:
|
||||
timestamp = None
|
||||
# Allow up to 2 seconds of time drift before forcibly re-syncing, since
|
||||
# +/- 1 second can happen just due to scheduler timing.
|
||||
if timestamp is not None and not before - 2.0 <= timestamp + parsed_samples <= after + 2.0:
|
||||
if verbose:
|
||||
print("Lost sample time sync at: " +
|
||||
str(datetime.fromtimestamp(timestamp + parsed_samples, tz=timezone.utc)))
|
||||
timestamp = None
|
||||
if timestamp is None:
|
||||
timestamp = int(before)
|
||||
if verbose and gstate.query_done:
|
||||
print("Establishing new time base: {0} -> {1}".format(
|
||||
new_counter, datetime.fromtimestamp(timestamp, tz=timezone.utc)))
|
||||
timestamp -= parsed_samples
|
||||
|
||||
for i in range(parsed_samples):
|
||||
timestamp += 1
|
||||
gstate.points.append({
|
||||
"measurement": BULK_MEASUREMENT,
|
||||
"tags": {
|
||||
"id": gstate.dish_id
|
||||
},
|
||||
"time": timestamp,
|
||||
"fields": {k: v[i] for k, v in bulk.items() if v[i] is not None},
|
||||
})
|
||||
|
||||
# save off counter value for script restart
|
||||
if parsed_samples:
|
||||
gstate.points[-1]["fields"]["counter"] = new_counter
|
||||
|
||||
gstate.counter = new_counter
|
||||
gstate.timestamp = timestamp
|
||||
|
||||
# This is here and not before the points being processed because if the
|
||||
# query previously failed, there will be points that were processed in
|
||||
# a prior loop. This avoids having to handle that as a special case.
|
||||
if not gstate.query_done:
|
||||
try:
|
||||
db_counter, db_timestamp = query_counter(client, timestamp, len(gstate.points))
|
||||
except Exception as e:
|
||||
# could be temporary outage, so try again next time
|
||||
conn_error("Failed querying InfluxDB for prior count: %s", str(e))
|
||||
return
|
||||
gstate.query_done = True
|
||||
start_counter = new_counter - len(gstate.points)
|
||||
if db_counter and start_counter <= db_counter < new_counter:
|
||||
del gstate.points[:db_counter - start_counter]
|
||||
if before - 2.0 <= db_timestamp + len(gstate.points) <= after + 2.0:
|
||||
if verbose:
|
||||
print("Using existing time base: {0} -> {1}".format(
|
||||
db_counter, datetime.fromtimestamp(db_timestamp, tz=timezone.utc)))
|
||||
for point in gstate.points:
|
||||
db_timestamp += 1
|
||||
point["time"] = db_timestamp
|
||||
gstate.timestamp = db_timestamp
|
||||
return
|
||||
if verbose:
|
||||
print("Establishing new time base: {0} -> {1}".format(
|
||||
new_counter, datetime.fromtimestamp(timestamp, tz=timezone.utc)))
|
||||
|
||||
def process_ping_stats():
|
||||
timestamp = time.time()
|
||||
|
||||
general, pd_stats, rl_stats = starlink_grpc.history_ping_stats(samples, verbose)
|
||||
|
||||
all_stats = general.copy()
|
||||
all_stats.update(pd_stats)
|
||||
if run_lengths:
|
||||
for k, v in rl_stats.items():
|
||||
if k.startswith("run_"):
|
||||
for i, subv in enumerate(v, start=1):
|
||||
all_stats[k + "_" + str(i)] = subv
|
||||
else:
|
||||
all_stats[k] = v
|
||||
|
||||
gstate.points.append({
|
||||
"measurement": PING_MEASUREMENT,
|
||||
"tags": {
|
||||
"id": gstate.dish_id
|
||||
},
|
||||
"time": int(timestamp),
|
||||
"fields": all_stats,
|
||||
})
|
||||
|
||||
def loop_body(client):
|
||||
if gstate.dish_id is None:
|
||||
try:
|
||||
gstate.dish_id = starlink_grpc.get_id()
|
||||
if verbose:
|
||||
print("Using dish ID: " + gstate.dish_id)
|
||||
except starlink_grpc.GrpcError as e:
|
||||
conn_error("Failure getting dish ID: %s", str(e))
|
||||
return 1
|
||||
|
||||
if bulk_mode:
|
||||
try:
|
||||
process_bulk_data(client)
|
||||
except starlink_grpc.GrpcError as e:
|
||||
conn_error("Failure getting history: %s", str(e))
|
||||
return 1
|
||||
else:
|
||||
try:
|
||||
process_ping_stats()
|
||||
except starlink_grpc.GrpcError as e:
|
||||
conn_error("Failure getting ping stats: %s", str(e))
|
||||
return 1
|
||||
|
||||
if verbose:
|
||||
print("Data points queued: " + str(len(gstate.points)))
|
||||
|
||||
if len(gstate.points) >= flush_limit:
|
||||
return flush_points(client)
|
||||
|
||||
return 0
|
||||
|
||||
if "verify_ssl" in icargs and not icargs["verify_ssl"]:
|
||||
# user has explicitly said be insecure, so don't warn about it
|
||||
warnings.filterwarnings("ignore", message="Unverified HTTPS request")
|
||||
|
||||
signal.signal(signal.SIGTERM, handle_sigterm)
|
||||
try:
|
||||
# attempt to hack around breakage between influxdb-python client and 2.0 server:
|
||||
influx_client = InfluxDBClient(**icargs, headers={"Accept": "application/json"})
|
||||
except TypeError:
|
||||
# ...unless influxdb-python package version is too old
|
||||
influx_client = InfluxDBClient(**icargs)
|
||||
try:
|
||||
next_loop = time.monotonic()
|
||||
while True:
|
||||
rc = loop_body(influx_client)
|
||||
if loop_time > 0:
|
||||
now = time.monotonic()
|
||||
next_loop = max(next_loop + loop_time, now)
|
||||
time.sleep(next_loop - now)
|
||||
else:
|
||||
break
|
||||
except Terminated:
|
||||
pass
|
||||
finally:
|
||||
if gstate.points:
|
||||
rc = flush_points(influx_client)
|
||||
influx_client.close()
|
||||
|
||||
sys.exit(rc)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
|
|
@ -1,185 +0,0 @@
|
|||
#!/usr/bin/python3
|
||||
######################################################################
|
||||
#
|
||||
# Publish Starlink user terminal packet loss statistics to a MQTT
|
||||
# broker.
|
||||
#
|
||||
# This script examines the most recent samples from the history data,
|
||||
# computes several different metrics related to packet loss, and
|
||||
# publishes those to the specified MQTT broker.
|
||||
#
|
||||
######################################################################
|
||||
|
||||
import getopt
|
||||
import logging
|
||||
import sys
|
||||
import time
|
||||
|
||||
try:
|
||||
import ssl
|
||||
ssl_ok = True
|
||||
except ImportError:
|
||||
ssl_ok = False
|
||||
|
||||
import paho.mqtt.publish
|
||||
|
||||
import starlink_grpc
|
||||
|
||||
|
||||
def main():
|
||||
arg_error = False
|
||||
|
||||
try:
|
||||
opts, args = getopt.getopt(sys.argv[1:], "ahn:p:rs:t:vC:ISP:U:")
|
||||
except getopt.GetoptError as err:
|
||||
print(str(err))
|
||||
arg_error = True
|
||||
|
||||
# Default to 1 hour worth of data samples.
|
||||
samples_default = 3600
|
||||
samples = None
|
||||
print_usage = False
|
||||
verbose = False
|
||||
default_loop_time = 0
|
||||
loop_time = default_loop_time
|
||||
run_lengths = False
|
||||
host_default = "localhost"
|
||||
mqargs = {"hostname": host_default}
|
||||
username = None
|
||||
password = None
|
||||
|
||||
if not arg_error:
|
||||
if len(args) > 0:
|
||||
arg_error = True
|
||||
else:
|
||||
for opt, arg in opts:
|
||||
if opt == "-a":
|
||||
samples = -1
|
||||
elif opt == "-h":
|
||||
print_usage = True
|
||||
elif opt == "-n":
|
||||
mqargs["hostname"] = arg
|
||||
elif opt == "-p":
|
||||
mqargs["port"] = int(arg)
|
||||
elif opt == "-r":
|
||||
run_lengths = True
|
||||
elif opt == "-s":
|
||||
samples = int(arg)
|
||||
elif opt == "-t":
|
||||
loop_time = float(arg)
|
||||
elif opt == "-v":
|
||||
verbose = True
|
||||
elif opt == "-C":
|
||||
mqargs["tls"] = {"ca_certs": arg}
|
||||
elif opt == "-I":
|
||||
if ssl_ok:
|
||||
mqargs["tls"] = {"cert_reqs": ssl.CERT_NONE}
|
||||
else:
|
||||
print("No SSL support found")
|
||||
sys.exit(1)
|
||||
elif opt == "-P":
|
||||
password = arg
|
||||
elif opt == "-S":
|
||||
mqargs["tls"] = {}
|
||||
elif opt == "-U":
|
||||
username = arg
|
||||
|
||||
if username is None and password is not None:
|
||||
print("Password authentication requires username to be set")
|
||||
arg_error = True
|
||||
|
||||
if print_usage or arg_error:
|
||||
print("Usage: " + sys.argv[0] + " [options...]")
|
||||
print("Options:")
|
||||
print(" -a: Parse all valid samples")
|
||||
print(" -h: Be helpful")
|
||||
print(" -n <name>: Hostname of MQTT broker, default: " + host_default)
|
||||
print(" -p <num>: Port number to use on MQTT broker")
|
||||
print(" -r: Include ping drop run length stats")
|
||||
print(" -s <num>: Number of data samples to parse, default: loop interval,")
|
||||
print(" if set, else " + str(samples_default))
|
||||
print(" -t <num>: Loop interval in seconds or 0 for no loop, default: " +
|
||||
str(default_loop_time))
|
||||
print(" -v: Be verbose")
|
||||
print(" -C <filename>: Enable SSL/TLS using specified CA cert to verify broker")
|
||||
print(" -I: Enable SSL/TLS but disable certificate verification (INSECURE!)")
|
||||
print(" -P: Set password for username/password authentication")
|
||||
print(" -S: Enable SSL/TLS using default CA cert")
|
||||
print(" -U: Set username for authentication")
|
||||
sys.exit(1 if arg_error else 0)
|
||||
|
||||
if samples is None:
|
||||
samples = int(loop_time) if loop_time > 0 else samples_default
|
||||
|
||||
if username is not None:
|
||||
mqargs["auth"] = {"username": username}
|
||||
if password is not None:
|
||||
mqargs["auth"]["password"] = password
|
||||
|
||||
logging.basicConfig(format="%(levelname)s: %(message)s")
|
||||
|
||||
class GlobalState:
|
||||
pass
|
||||
|
||||
gstate = GlobalState()
|
||||
gstate.dish_id = None
|
||||
|
||||
def conn_error(msg, *args):
|
||||
# Connection errors that happen in an interval loop are not critical
|
||||
# failures, but are interesting enough to print in non-verbose mode.
|
||||
if loop_time > 0:
|
||||
print(msg % args)
|
||||
else:
|
||||
logging.error(msg, *args)
|
||||
|
||||
def loop_body():
|
||||
if gstate.dish_id is None:
|
||||
try:
|
||||
gstate.dish_id = starlink_grpc.get_id()
|
||||
if verbose:
|
||||
print("Using dish ID: " + gstate.dish_id)
|
||||
except starlink_grpc.GrpcError as e:
|
||||
conn_error("Failure getting dish ID: %s", str(e))
|
||||
return 1
|
||||
|
||||
try:
|
||||
g_stats, pd_stats, rl_stats = starlink_grpc.history_ping_stats(samples, verbose)
|
||||
except starlink_grpc.GrpcError as e:
|
||||
conn_error("Failure getting ping stats: %s", str(e))
|
||||
return 1
|
||||
|
||||
topic_prefix = "starlink/dish_ping_stats/" + gstate.dish_id + "/"
|
||||
msgs = [(topic_prefix + k, v, 0, False) for k, v in g_stats.items()]
|
||||
msgs.extend([(topic_prefix + k, v, 0, False) for k, v in pd_stats.items()])
|
||||
if run_lengths:
|
||||
for k, v in rl_stats.items():
|
||||
if k.startswith("run_"):
|
||||
msgs.append((topic_prefix + k, ",".join(str(x) for x in v), 0, False))
|
||||
else:
|
||||
msgs.append((topic_prefix + k, v, 0, False))
|
||||
|
||||
try:
|
||||
paho.mqtt.publish.multiple(msgs, client_id=gstate.dish_id, **mqargs)
|
||||
if verbose:
|
||||
print("Successfully published to MQTT broker")
|
||||
except Exception as e:
|
||||
conn_error("Failed publishing to MQTT broker: %s", str(e))
|
||||
return 1
|
||||
|
||||
return 0
|
||||
|
||||
next_loop = time.monotonic()
|
||||
while True:
|
||||
rc = loop_body()
|
||||
if loop_time > 0:
|
||||
now = time.monotonic()
|
||||
next_loop = max(next_loop + loop_time, now)
|
||||
time.sleep(next_loop - now)
|
||||
else:
|
||||
break
|
||||
|
||||
sys.exit(rc)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
|
|
@ -1,151 +0,0 @@
|
|||
#!/usr/bin/python3
|
||||
######################################################################
|
||||
#
|
||||
# Equivalent script to parseJsonHistory.py, except integrating the
|
||||
# gRPC calls, instead of relying on separate invocation of grpcurl.
|
||||
#
|
||||
# This script examines the most recent samples from the history data
|
||||
# and computes several different metrics related to packet loss. By
|
||||
# default, it will print the results in CSV format.
|
||||
#
|
||||
######################################################################
|
||||
|
||||
import datetime
|
||||
import getopt
|
||||
import logging
|
||||
import sys
|
||||
import time
|
||||
|
||||
import starlink_grpc
|
||||
|
||||
|
||||
def main():
|
||||
arg_error = False
|
||||
|
||||
try:
|
||||
opts, args = getopt.getopt(sys.argv[1:], "ahrs:t:vH")
|
||||
except getopt.GetoptError as err:
|
||||
print(str(err))
|
||||
arg_error = True
|
||||
|
||||
# Default to 1 hour worth of data samples.
|
||||
samples_default = 3600
|
||||
samples = None
|
||||
print_usage = False
|
||||
verbose = False
|
||||
default_loop_time = 0
|
||||
loop_time = default_loop_time
|
||||
run_lengths = False
|
||||
print_header = False
|
||||
|
||||
if not arg_error:
|
||||
if len(args) > 0:
|
||||
arg_error = True
|
||||
else:
|
||||
for opt, arg in opts:
|
||||
if opt == "-a":
|
||||
samples = -1
|
||||
elif opt == "-h":
|
||||
print_usage = True
|
||||
elif opt == "-r":
|
||||
run_lengths = True
|
||||
elif opt == "-s":
|
||||
samples = int(arg)
|
||||
elif opt == "-t":
|
||||
loop_time = float(arg)
|
||||
elif opt == "-v":
|
||||
verbose = True
|
||||
elif opt == "-H":
|
||||
print_header = True
|
||||
|
||||
if print_usage or arg_error:
|
||||
print("Usage: " + sys.argv[0] + " [options...]")
|
||||
print("Options:")
|
||||
print(" -a: Parse all valid samples")
|
||||
print(" -h: Be helpful")
|
||||
print(" -r: Include ping drop run length stats")
|
||||
print(" -s <num>: Number of data samples to parse, default: loop interval,")
|
||||
print(" if set, else " + str(samples_default))
|
||||
print(" -t <num>: Loop interval in seconds or 0 for no loop, default: " +
|
||||
str(default_loop_time))
|
||||
print(" -v: Be verbose")
|
||||
print(" -H: print CSV header instead of parsing history data")
|
||||
sys.exit(1 if arg_error else 0)
|
||||
|
||||
if samples is None:
|
||||
samples = int(loop_time) if loop_time > 0 else samples_default
|
||||
|
||||
logging.basicConfig(format="%(levelname)s: %(message)s")
|
||||
|
||||
g_fields, pd_fields, rl_fields = starlink_grpc.history_ping_field_names()
|
||||
|
||||
if print_header:
|
||||
header = ["datetimestamp_utc"]
|
||||
header.extend(g_fields)
|
||||
header.extend(pd_fields)
|
||||
if run_lengths:
|
||||
for field in rl_fields:
|
||||
if field.startswith("run_"):
|
||||
header.extend(field + "_" + str(x) for x in range(1, 61))
|
||||
else:
|
||||
header.append(field)
|
||||
print(",".join(header))
|
||||
sys.exit(0)
|
||||
|
||||
def loop_body():
|
||||
timestamp = datetime.datetime.utcnow()
|
||||
|
||||
try:
|
||||
g_stats, pd_stats, rl_stats = starlink_grpc.history_ping_stats(samples, verbose)
|
||||
except starlink_grpc.GrpcError as e:
|
||||
logging.error("Failure getting ping stats: %s", str(e))
|
||||
return 1
|
||||
|
||||
if verbose:
|
||||
print("Parsed samples: " + str(g_stats["samples"]))
|
||||
print("Total ping drop: " + str(pd_stats["total_ping_drop"]))
|
||||
print("Count of drop == 1: " + str(pd_stats["count_full_ping_drop"]))
|
||||
print("Obstructed: " + str(pd_stats["count_obstructed"]))
|
||||
print("Obstructed ping drop: " + str(pd_stats["total_obstructed_ping_drop"]))
|
||||
print("Obstructed drop == 1: " + str(pd_stats["count_full_obstructed_ping_drop"]))
|
||||
print("Unscheduled: " + str(pd_stats["count_unscheduled"]))
|
||||
print("Unscheduled ping drop: " + str(pd_stats["total_unscheduled_ping_drop"]))
|
||||
print("Unscheduled drop == 1: " + str(pd_stats["count_full_unscheduled_ping_drop"]))
|
||||
if run_lengths:
|
||||
print("Initial drop run fragment: " + str(rl_stats["init_run_fragment"]))
|
||||
print("Final drop run fragment: " + str(rl_stats["final_run_fragment"]))
|
||||
print("Per-second drop runs: " +
|
||||
", ".join(str(x) for x in rl_stats["run_seconds"]))
|
||||
print("Per-minute drop runs: " +
|
||||
", ".join(str(x) for x in rl_stats["run_minutes"]))
|
||||
if loop_time > 0:
|
||||
print()
|
||||
else:
|
||||
csv_data = [timestamp.replace(microsecond=0).isoformat()]
|
||||
csv_data.extend(str(g_stats[field]) for field in g_fields)
|
||||
csv_data.extend(str(pd_stats[field]) for field in pd_fields)
|
||||
if run_lengths:
|
||||
for field in rl_fields:
|
||||
if field.startswith("run_"):
|
||||
csv_data.extend(str(substat) for substat in rl_stats[field])
|
||||
else:
|
||||
csv_data.append(str(rl_stats[field]))
|
||||
print(",".join(csv_data))
|
||||
|
||||
return 0
|
||||
|
||||
next_loop = time.monotonic()
|
||||
while True:
|
||||
rc = loop_body()
|
||||
if loop_time > 0:
|
||||
now = time.monotonic()
|
||||
next_loop = max(next_loop + loop_time, now)
|
||||
time.sleep(next_loop - now)
|
||||
else:
|
||||
break
|
||||
|
||||
sys.exit(rc)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
147
dishStatusCsv.py
147
dishStatusCsv.py
|
|
@ -1,147 +0,0 @@
|
|||
#!/usr/bin/python3
|
||||
######################################################################
|
||||
#
|
||||
# Output Starlink user terminal status info in CSV format.
|
||||
#
|
||||
# This script pulls the current status and prints to stdout either
|
||||
# once or in a periodic loop.
|
||||
#
|
||||
######################################################################
|
||||
|
||||
import datetime
|
||||
import getopt
|
||||
import logging
|
||||
import sys
|
||||
import time
|
||||
|
||||
import grpc
|
||||
|
||||
import spacex.api.device.device_pb2
|
||||
import spacex.api.device.device_pb2_grpc
|
||||
|
||||
|
||||
def main():
|
||||
arg_error = False
|
||||
|
||||
try:
|
||||
opts, args = getopt.getopt(sys.argv[1:], "ht:H")
|
||||
except getopt.GetoptError as err:
|
||||
print(str(err))
|
||||
arg_error = True
|
||||
|
||||
print_usage = False
|
||||
default_loop_time = 0
|
||||
loop_time = default_loop_time
|
||||
print_header = False
|
||||
|
||||
if not arg_error:
|
||||
if len(args) > 0:
|
||||
arg_error = True
|
||||
else:
|
||||
for opt, arg in opts:
|
||||
if opt == "-h":
|
||||
print_usage = True
|
||||
elif opt == "-t":
|
||||
loop_time = float(arg)
|
||||
elif opt == "-H":
|
||||
print_header = True
|
||||
|
||||
if print_usage or arg_error:
|
||||
print("Usage: " + sys.argv[0] + " [options...]")
|
||||
print("Options:")
|
||||
print(" -h: Be helpful")
|
||||
print(" -t <num>: Loop interval in seconds or 0 for no loop, default: " +
|
||||
str(default_loop_time))
|
||||
print(" -H: print CSV header instead of parsing file")
|
||||
sys.exit(1 if arg_error else 0)
|
||||
|
||||
logging.basicConfig(format="%(levelname)s: %(message)s")
|
||||
|
||||
if print_header:
|
||||
header = [
|
||||
"datetimestamp_utc",
|
||||
"hardware_version",
|
||||
"software_version",
|
||||
"state",
|
||||
"uptime",
|
||||
"snr",
|
||||
"seconds_to_first_nonempty_slot",
|
||||
"pop_ping_drop_rate",
|
||||
"downlink_throughput_bps",
|
||||
"uplink_throughput_bps",
|
||||
"pop_ping_latency_ms",
|
||||
"alerts",
|
||||
"fraction_obstructed",
|
||||
"currently_obstructed",
|
||||
"seconds_obstructed",
|
||||
]
|
||||
header.extend("wedges_fraction_obstructed_" + str(x) for x in range(12))
|
||||
print(",".join(header))
|
||||
sys.exit(0)
|
||||
|
||||
def loop_body():
|
||||
timestamp = datetime.datetime.utcnow()
|
||||
|
||||
try:
|
||||
with grpc.insecure_channel("192.168.100.1:9200") as channel:
|
||||
stub = spacex.api.device.device_pb2_grpc.DeviceStub(channel)
|
||||
response = stub.Handle(spacex.api.device.device_pb2.Request(get_status={}))
|
||||
|
||||
status = response.dish_get_status
|
||||
|
||||
# More alerts may be added in future, so rather than list them individually,
|
||||
# build a bit field based on field numbers of the DishAlerts message.
|
||||
alert_bits = 0
|
||||
for alert in status.alerts.ListFields():
|
||||
alert_bits |= (1 if alert[1] else 0) << (alert[0].number - 1)
|
||||
|
||||
csv_data = [
|
||||
timestamp.replace(microsecond=0).isoformat(),
|
||||
status.device_info.id,
|
||||
status.device_info.hardware_version,
|
||||
status.device_info.software_version,
|
||||
spacex.api.device.dish_pb2.DishState.Name(status.state),
|
||||
]
|
||||
csv_data.extend(
|
||||
str(x) for x in [
|
||||
status.device_state.uptime_s,
|
||||
status.snr,
|
||||
status.seconds_to_first_nonempty_slot,
|
||||
status.pop_ping_drop_rate,
|
||||
status.downlink_throughput_bps,
|
||||
status.uplink_throughput_bps,
|
||||
status.pop_ping_latency_ms,
|
||||
alert_bits,
|
||||
status.obstruction_stats.fraction_obstructed,
|
||||
status.obstruction_stats.currently_obstructed,
|
||||
status.obstruction_stats.last_24h_obstructed_s,
|
||||
])
|
||||
csv_data.extend(str(x) for x in status.obstruction_stats.wedge_abs_fraction_obstructed)
|
||||
rc = 0
|
||||
except grpc.RpcError:
|
||||
if loop_time <= 0:
|
||||
logging.error("Failed getting status info")
|
||||
csv_data = [
|
||||
timestamp.replace(microsecond=0).isoformat(), "", "", "", "DISH_UNREACHABLE"
|
||||
]
|
||||
rc = 1
|
||||
|
||||
print(",".join(csv_data))
|
||||
|
||||
return rc
|
||||
|
||||
next_loop = time.monotonic()
|
||||
while True:
|
||||
rc = loop_body()
|
||||
if loop_time > 0:
|
||||
now = time.monotonic()
|
||||
next_loop = max(next_loop + loop_time, now)
|
||||
time.sleep(next_loop - now)
|
||||
else:
|
||||
break
|
||||
|
||||
sys.exit(rc)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
|
|
@ -1,283 +0,0 @@
|
|||
#!/usr/bin/python3
|
||||
######################################################################
|
||||
#
|
||||
# Write Starlink user terminal status info to an InfluxDB database.
|
||||
#
|
||||
# This script will poll current status and write it to the specified
|
||||
# InfluxDB database either once or in a periodic loop.
|
||||
#
|
||||
######################################################################
|
||||
|
||||
import getopt
|
||||
import logging
|
||||
import os
|
||||
import signal
|
||||
import sys
|
||||
import time
|
||||
import warnings
|
||||
|
||||
import grpc
|
||||
from influxdb import InfluxDBClient
|
||||
from influxdb import SeriesHelper
|
||||
|
||||
import spacex.api.device.device_pb2
|
||||
import spacex.api.device.device_pb2_grpc
|
||||
|
||||
|
||||
class Terminated(Exception):
|
||||
pass
|
||||
|
||||
|
||||
def handle_sigterm(signum, frame):
|
||||
# Turn SIGTERM into an exception so main loop can clean up
|
||||
raise Terminated()
|
||||
|
||||
|
||||
def main():
|
||||
arg_error = False
|
||||
|
||||
try:
|
||||
opts, args = getopt.getopt(sys.argv[1:], "hn:p:t:vC:D:IP:R:SU:")
|
||||
except getopt.GetoptError as err:
|
||||
print(str(err))
|
||||
arg_error = True
|
||||
|
||||
print_usage = False
|
||||
verbose = False
|
||||
default_loop_time = 0
|
||||
loop_time = default_loop_time
|
||||
host_default = "localhost"
|
||||
database_default = "starlinkstats"
|
||||
icargs = {"host": host_default, "timeout": 5, "database": database_default}
|
||||
rp = None
|
||||
flush_limit = 6
|
||||
|
||||
# For each of these check they are both set and not empty string
|
||||
influxdb_host = os.environ.get("INFLUXDB_HOST")
|
||||
if influxdb_host:
|
||||
icargs["host"] = influxdb_host
|
||||
influxdb_port = os.environ.get("INFLUXDB_PORT")
|
||||
if influxdb_port:
|
||||
icargs["port"] = int(influxdb_port)
|
||||
influxdb_user = os.environ.get("INFLUXDB_USER")
|
||||
if influxdb_user:
|
||||
icargs["username"] = influxdb_user
|
||||
influxdb_pwd = os.environ.get("INFLUXDB_PWD")
|
||||
if influxdb_pwd:
|
||||
icargs["password"] = influxdb_pwd
|
||||
influxdb_db = os.environ.get("INFLUXDB_DB")
|
||||
if influxdb_db:
|
||||
icargs["database"] = influxdb_db
|
||||
influxdb_rp = os.environ.get("INFLUXDB_RP")
|
||||
if influxdb_rp:
|
||||
rp = influxdb_rp
|
||||
influxdb_ssl = os.environ.get("INFLUXDB_SSL")
|
||||
if influxdb_ssl:
|
||||
icargs["ssl"] = True
|
||||
if influxdb_ssl.lower() == "secure":
|
||||
icargs["verify_ssl"] = True
|
||||
elif influxdb_ssl.lower() == "insecure":
|
||||
icargs["verify_ssl"] = False
|
||||
else:
|
||||
icargs["verify_ssl"] = influxdb_ssl
|
||||
|
||||
if not arg_error:
|
||||
if len(args) > 0:
|
||||
arg_error = True
|
||||
else:
|
||||
for opt, arg in opts:
|
||||
if opt == "-h":
|
||||
print_usage = True
|
||||
elif opt == "-n":
|
||||
icargs["host"] = arg
|
||||
elif opt == "-p":
|
||||
icargs["port"] = int(arg)
|
||||
elif opt == "-t":
|
||||
loop_time = int(arg)
|
||||
elif opt == "-v":
|
||||
verbose = True
|
||||
elif opt == "-C":
|
||||
icargs["ssl"] = True
|
||||
icargs["verify_ssl"] = arg
|
||||
elif opt == "-D":
|
||||
icargs["database"] = arg
|
||||
elif opt == "-I":
|
||||
icargs["ssl"] = True
|
||||
icargs["verify_ssl"] = False
|
||||
elif opt == "-P":
|
||||
icargs["password"] = arg
|
||||
elif opt == "-R":
|
||||
rp = arg
|
||||
elif opt == "-S":
|
||||
icargs["ssl"] = True
|
||||
icargs["verify_ssl"] = True
|
||||
elif opt == "-U":
|
||||
icargs["username"] = arg
|
||||
|
||||
if "password" in icargs and "username" not in icargs:
|
||||
print("Password authentication requires username to be set")
|
||||
arg_error = True
|
||||
|
||||
if print_usage or arg_error:
|
||||
print("Usage: " + sys.argv[0] + " [options...]")
|
||||
print("Options:")
|
||||
print(" -h: Be helpful")
|
||||
print(" -n <name>: Hostname of InfluxDB server, default: " + host_default)
|
||||
print(" -p <num>: Port number to use on InfluxDB server")
|
||||
print(" -t <num>: Loop interval in seconds or 0 for no loop, default: " +
|
||||
str(default_loop_time))
|
||||
print(" -v: Be verbose")
|
||||
print(" -C <filename>: Enable SSL/TLS using specified CA cert to verify server")
|
||||
print(" -D <name>: Database name to use, default: " + database_default)
|
||||
print(" -I: Enable SSL/TLS but disable certificate verification (INSECURE!)")
|
||||
print(" -P <word>: Set password for authentication")
|
||||
print(" -R <name>: Retention policy name to use")
|
||||
print(" -S: Enable SSL/TLS using default CA cert")
|
||||
print(" -U <name>: Set username for authentication")
|
||||
sys.exit(1 if arg_error else 0)
|
||||
|
||||
logging.basicConfig(format="%(levelname)s: %(message)s")
|
||||
|
||||
class GlobalState:
|
||||
pass
|
||||
|
||||
gstate = GlobalState()
|
||||
gstate.dish_channel = None
|
||||
gstate.dish_id = None
|
||||
gstate.pending = 0
|
||||
|
||||
class DeviceStatusSeries(SeriesHelper):
|
||||
class Meta:
|
||||
series_name = "spacex.starlink.user_terminal.status"
|
||||
fields = [
|
||||
"hardware_version",
|
||||
"software_version",
|
||||
"state",
|
||||
"alert_motors_stuck",
|
||||
"alert_thermal_throttle",
|
||||
"alert_thermal_shutdown",
|
||||
"alert_unexpected_location",
|
||||
"snr",
|
||||
"seconds_to_first_nonempty_slot",
|
||||
"pop_ping_drop_rate",
|
||||
"downlink_throughput_bps",
|
||||
"uplink_throughput_bps",
|
||||
"pop_ping_latency_ms",
|
||||
"currently_obstructed",
|
||||
"fraction_obstructed",
|
||||
]
|
||||
tags = ["id"]
|
||||
retention_policy = rp
|
||||
|
||||
def conn_error(msg, *args):
|
||||
# Connection errors that happen in an interval loop are not critical
|
||||
# failures, but are interesting enough to print in non-verbose mode.
|
||||
if loop_time > 0:
|
||||
print(msg % args)
|
||||
else:
|
||||
logging.error(msg, *args)
|
||||
|
||||
def flush_pending(client):
|
||||
try:
|
||||
DeviceStatusSeries.commit(client)
|
||||
if verbose:
|
||||
print("Data points written: " + str(gstate.pending))
|
||||
gstate.pending = 0
|
||||
except Exception as e:
|
||||
conn_error("Failed writing to InfluxDB database: %s", str(e))
|
||||
return 1
|
||||
|
||||
return 0
|
||||
|
||||
def get_status_retry():
|
||||
"""Try getting the status at most twice"""
|
||||
|
||||
channel_reused = True
|
||||
while True:
|
||||
try:
|
||||
if gstate.dish_channel is None:
|
||||
gstate.dish_channel = grpc.insecure_channel("192.168.100.1:9200")
|
||||
channel_reused = False
|
||||
stub = spacex.api.device.device_pb2_grpc.DeviceStub(gstate.dish_channel)
|
||||
response = stub.Handle(spacex.api.device.device_pb2.Request(get_status={}))
|
||||
return response.dish_get_status
|
||||
except grpc.RpcError:
|
||||
gstate.dish_channel.close()
|
||||
gstate.dish_channel = None
|
||||
if channel_reused:
|
||||
# If the channel was open already, the connection may have
|
||||
# been lost in the time since prior loop iteration, so after
|
||||
# closing it, retry once, in case the dish is now reachable.
|
||||
if verbose:
|
||||
print("Dish RPC channel error")
|
||||
else:
|
||||
raise
|
||||
|
||||
def loop_body(client):
|
||||
try:
|
||||
status = get_status_retry()
|
||||
DeviceStatusSeries(id=status.device_info.id,
|
||||
hardware_version=status.device_info.hardware_version,
|
||||
software_version=status.device_info.software_version,
|
||||
state=spacex.api.device.dish_pb2.DishState.Name(status.state),
|
||||
alert_motors_stuck=status.alerts.motors_stuck,
|
||||
alert_thermal_throttle=status.alerts.thermal_throttle,
|
||||
alert_thermal_shutdown=status.alerts.thermal_shutdown,
|
||||
alert_unexpected_location=status.alerts.unexpected_location,
|
||||
snr=status.snr,
|
||||
seconds_to_first_nonempty_slot=status.seconds_to_first_nonempty_slot,
|
||||
pop_ping_drop_rate=status.pop_ping_drop_rate,
|
||||
downlink_throughput_bps=status.downlink_throughput_bps,
|
||||
uplink_throughput_bps=status.uplink_throughput_bps,
|
||||
pop_ping_latency_ms=status.pop_ping_latency_ms,
|
||||
currently_obstructed=status.obstruction_stats.currently_obstructed,
|
||||
fraction_obstructed=status.obstruction_stats.fraction_obstructed)
|
||||
gstate.dish_id = status.device_info.id
|
||||
except grpc.RpcError:
|
||||
if gstate.dish_id is None:
|
||||
conn_error("Dish unreachable and ID unknown, so not recording state")
|
||||
return 1
|
||||
else:
|
||||
if verbose:
|
||||
print("Dish unreachable")
|
||||
DeviceStatusSeries(id=gstate.dish_id, state="DISH_UNREACHABLE")
|
||||
|
||||
gstate.pending += 1
|
||||
if verbose:
|
||||
print("Data points queued: " + str(gstate.pending))
|
||||
if gstate.pending >= flush_limit:
|
||||
return flush_pending(client)
|
||||
|
||||
return 0
|
||||
|
||||
if "verify_ssl" in icargs and not icargs["verify_ssl"]:
|
||||
# user has explicitly said be insecure, so don't warn about it
|
||||
warnings.filterwarnings("ignore", message="Unverified HTTPS request")
|
||||
|
||||
signal.signal(signal.SIGTERM, handle_sigterm)
|
||||
influx_client = InfluxDBClient(**icargs)
|
||||
try:
|
||||
next_loop = time.monotonic()
|
||||
while True:
|
||||
rc = loop_body(influx_client)
|
||||
if loop_time > 0:
|
||||
now = time.monotonic()
|
||||
next_loop = max(next_loop + loop_time, now)
|
||||
time.sleep(next_loop - now)
|
||||
else:
|
||||
break
|
||||
except Terminated:
|
||||
pass
|
||||
finally:
|
||||
# Flush on error/exit
|
||||
if gstate.pending:
|
||||
rc = flush_pending(influx_client)
|
||||
influx_client.close()
|
||||
if gstate.dish_channel is not None:
|
||||
gstate.dish_channel.close()
|
||||
|
||||
sys.exit(rc)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
|
|
@ -1,188 +0,0 @@
|
|||
#!/usr/bin/python3
|
||||
######################################################################
|
||||
#
|
||||
# Publish Starlink user terminal status info to a MQTT broker.
|
||||
#
|
||||
# This script pulls the current status and publishes it to the
|
||||
# specified MQTT broker either once or in a periodic loop.
|
||||
#
|
||||
######################################################################
|
||||
|
||||
import getopt
|
||||
import logging
|
||||
import sys
|
||||
import time
|
||||
|
||||
try:
|
||||
import ssl
|
||||
ssl_ok = True
|
||||
except ImportError:
|
||||
ssl_ok = False
|
||||
|
||||
import grpc
|
||||
import paho.mqtt.publish
|
||||
|
||||
import spacex.api.device.device_pb2
|
||||
import spacex.api.device.device_pb2_grpc
|
||||
|
||||
|
||||
def main():
|
||||
arg_error = False
|
||||
|
||||
try:
|
||||
opts, args = getopt.getopt(sys.argv[1:], "hn:p:t:vC:ISP:U:")
|
||||
except getopt.GetoptError as err:
|
||||
print(str(err))
|
||||
arg_error = True
|
||||
|
||||
print_usage = False
|
||||
verbose = False
|
||||
default_loop_time = 0
|
||||
loop_time = default_loop_time
|
||||
host_default = "localhost"
|
||||
mqargs = {"hostname": host_default}
|
||||
username = None
|
||||
password = None
|
||||
|
||||
if not arg_error:
|
||||
if len(args) > 0:
|
||||
arg_error = True
|
||||
else:
|
||||
for opt, arg in opts:
|
||||
if opt == "-h":
|
||||
print_usage = True
|
||||
elif opt == "-n":
|
||||
mqargs["hostname"] = arg
|
||||
elif opt == "-p":
|
||||
mqargs["port"] = int(arg)
|
||||
elif opt == "-t":
|
||||
loop_time = float(arg)
|
||||
elif opt == "-v":
|
||||
verbose = True
|
||||
elif opt == "-C":
|
||||
mqargs["tls"] = {"ca_certs": arg}
|
||||
elif opt == "-I":
|
||||
if ssl_ok:
|
||||
mqargs["tls"] = {"cert_reqs": ssl.CERT_NONE}
|
||||
else:
|
||||
print("No SSL support found")
|
||||
sys.exit(1)
|
||||
elif opt == "-P":
|
||||
password = arg
|
||||
elif opt == "-S":
|
||||
mqargs["tls"] = {}
|
||||
elif opt == "-U":
|
||||
username = arg
|
||||
|
||||
if username is None and password is not None:
|
||||
print("Password authentication requires username to be set")
|
||||
arg_error = True
|
||||
|
||||
if print_usage or arg_error:
|
||||
print("Usage: " + sys.argv[0] + " [options...]")
|
||||
print("Options:")
|
||||
print(" -h: Be helpful")
|
||||
print(" -n <name>: Hostname of MQTT broker, default: " + host_default)
|
||||
print(" -p <num>: Port number to use on MQTT broker")
|
||||
print(" -t <num>: Loop interval in seconds or 0 for no loop, default: " +
|
||||
str(default_loop_time))
|
||||
print(" -v: Be verbose")
|
||||
print(" -C <filename>: Enable SSL/TLS using specified CA cert to verify broker")
|
||||
print(" -I: Enable SSL/TLS but disable certificate verification (INSECURE!)")
|
||||
print(" -P: Set password for username/password authentication")
|
||||
print(" -S: Enable SSL/TLS using default CA cert")
|
||||
print(" -U: Set username for authentication")
|
||||
sys.exit(1 if arg_error else 0)
|
||||
|
||||
if username is not None:
|
||||
mqargs["auth"] = {"username": username}
|
||||
if password is not None:
|
||||
mqargs["auth"]["password"] = password
|
||||
|
||||
logging.basicConfig(format="%(levelname)s: %(message)s")
|
||||
|
||||
class GlobalState:
|
||||
pass
|
||||
|
||||
gstate = GlobalState()
|
||||
gstate.dish_id = None
|
||||
|
||||
def conn_error(msg, *args):
|
||||
# Connection errors that happen in an interval loop are not critical
|
||||
# failures, but are interesting enough to print in non-verbose mode.
|
||||
if loop_time > 0:
|
||||
print(msg % args)
|
||||
else:
|
||||
logging.error(msg, *args)
|
||||
|
||||
def loop_body():
|
||||
try:
|
||||
with grpc.insecure_channel("192.168.100.1:9200") as channel:
|
||||
stub = spacex.api.device.device_pb2_grpc.DeviceStub(channel)
|
||||
response = stub.Handle(spacex.api.device.device_pb2.Request(get_status={}))
|
||||
|
||||
status = response.dish_get_status
|
||||
|
||||
# More alerts may be added in future, so rather than list them individually,
|
||||
# build a bit field based on field numbers of the DishAlerts message.
|
||||
alert_bits = 0
|
||||
for alert in status.alerts.ListFields():
|
||||
alert_bits |= (1 if alert[1] else 0) << (alert[0].number - 1)
|
||||
|
||||
gstate.dish_id = status.device_info.id
|
||||
topic_prefix = "starlink/dish_status/" + gstate.dish_id + "/"
|
||||
msgs = [
|
||||
(topic_prefix + "hardware_version", status.device_info.hardware_version, 0, False),
|
||||
(topic_prefix + "software_version", status.device_info.software_version, 0, False),
|
||||
(topic_prefix + "state", spacex.api.device.dish_pb2.DishState.Name(status.state), 0, False),
|
||||
(topic_prefix + "uptime", status.device_state.uptime_s, 0, False),
|
||||
(topic_prefix + "snr", status.snr, 0, False),
|
||||
(topic_prefix + "seconds_to_first_nonempty_slot", status.seconds_to_first_nonempty_slot, 0, False),
|
||||
(topic_prefix + "pop_ping_drop_rate", status.pop_ping_drop_rate, 0, False),
|
||||
(topic_prefix + "downlink_throughput_bps", status.downlink_throughput_bps, 0, False),
|
||||
(topic_prefix + "uplink_throughput_bps", status.uplink_throughput_bps, 0, False),
|
||||
(topic_prefix + "pop_ping_latency_ms", status.pop_ping_latency_ms, 0, False),
|
||||
(topic_prefix + "alerts", alert_bits, 0, False),
|
||||
(topic_prefix + "fraction_obstructed", status.obstruction_stats.fraction_obstructed, 0, False),
|
||||
(topic_prefix + "currently_obstructed", status.obstruction_stats.currently_obstructed, 0, False),
|
||||
# While the field name for this one implies it covers 24 hours, the
|
||||
# empirical evidence suggests it only covers 12 hours. It also resets
|
||||
# on dish reboot, so may not cover that whole period. Rather than try
|
||||
# to convey that complexity in the topic label, just be a bit vague:
|
||||
(topic_prefix + "seconds_obstructed", status.obstruction_stats.last_24h_obstructed_s, 0, False),
|
||||
(topic_prefix + "wedges_fraction_obstructed", ",".join(str(x) for x in status.obstruction_stats.wedge_abs_fraction_obstructed), 0, False),
|
||||
]
|
||||
except grpc.RpcError:
|
||||
if gstate.dish_id is None:
|
||||
conn_error("Dish unreachable and ID unknown, so not recording state")
|
||||
return 1
|
||||
if verbose:
|
||||
print("Dish unreachable")
|
||||
topic_prefix = "starlink/dish_status/" + gstate.dish_id + "/"
|
||||
msgs = [(topic_prefix + "state", "DISH_UNREACHABLE", 0, False)]
|
||||
|
||||
try:
|
||||
paho.mqtt.publish.multiple(msgs, client_id=gstate.dish_id, **mqargs)
|
||||
if verbose:
|
||||
print("Successfully published to MQTT broker")
|
||||
except Exception as e:
|
||||
conn_error("Failed publishing to MQTT broker: %s", str(e))
|
||||
return 1
|
||||
|
||||
return 0
|
||||
|
||||
next_loop = time.monotonic()
|
||||
while True:
|
||||
rc = loop_body()
|
||||
if loop_time > 0:
|
||||
now = time.monotonic()
|
||||
next_loop = max(next_loop + loop_time, now)
|
||||
time.sleep(next_loop - now)
|
||||
else:
|
||||
break
|
||||
|
||||
sys.exit(rc)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
270
dish_common.py
Normal file
270
dish_common.py
Normal file
|
|
@ -0,0 +1,270 @@
|
|||
"""Shared code among the dish_grpc_* commands
|
||||
|
||||
Note:
|
||||
|
||||
This module is not intended to be generically useful or to export a stable
|
||||
interface. Rather, it should be considered an implementation detail of the
|
||||
other scripts, and will change as needed.
|
||||
|
||||
For a module that exports an interface intended for general use, see
|
||||
starlink_grpc.
|
||||
"""
|
||||
|
||||
import argparse
|
||||
from datetime import datetime
|
||||
from datetime import timezone
|
||||
import logging
|
||||
import re
|
||||
import time
|
||||
|
||||
import starlink_grpc
|
||||
|
||||
BRACKETS_RE = re.compile(r"([^[]*)(\[((\d+),|)(\d*)\]|)$")
|
||||
SAMPLES_DEFAULT = 3600
|
||||
LOOP_TIME_DEFAULT = 0
|
||||
STATUS_MODES = ["status", "obstruction_detail", "alert_detail"]
|
||||
HISTORY_STATS_MODES = [
|
||||
"ping_drop", "ping_run_length", "ping_latency", "ping_loaded_latency", "usage"
|
||||
]
|
||||
UNGROUPED_MODES = []
|
||||
|
||||
|
||||
def create_arg_parser(output_description, bulk_history=True):
|
||||
"""Create an argparse parser and add the common command line options."""
|
||||
parser = argparse.ArgumentParser(
|
||||
description="Collect status and/or history data from a Starlink user terminal and " +
|
||||
output_description,
|
||||
epilog="Additional arguments can be read from a file by including @FILENAME as an "
|
||||
"option, where FILENAME is a path to a file that contains arguments, one per line.",
|
||||
fromfile_prefix_chars="@",
|
||||
add_help=False)
|
||||
|
||||
# need to remember this for later
|
||||
parser.bulk_history = bulk_history
|
||||
|
||||
group = parser.add_argument_group(title="General options")
|
||||
group.add_argument("-h", "--help", action="help", help="Be helpful")
|
||||
group.add_argument("-t",
|
||||
"--loop-interval",
|
||||
type=float,
|
||||
default=float(LOOP_TIME_DEFAULT),
|
||||
help="Loop interval in seconds or 0 for no loop, default: " +
|
||||
str(LOOP_TIME_DEFAULT))
|
||||
group.add_argument("-v", "--verbose", action="store_true", help="Be verbose")
|
||||
|
||||
group = parser.add_argument_group(title="History mode options")
|
||||
group.add_argument("-a",
|
||||
"--all-samples",
|
||||
action="store_const",
|
||||
const=-1,
|
||||
dest="samples",
|
||||
help="Parse all valid samples")
|
||||
if bulk_history:
|
||||
sample_help = ("Number of data samples to parse; in bulk mode, applies to first loop "
|
||||
"iteration only, default: -1 in bulk mode, loop interval if loop interval "
|
||||
"set, else " + str(SAMPLES_DEFAULT))
|
||||
else:
|
||||
sample_help = ("Number of data samples to parse, default: loop interval, if set, else " +
|
||||
str(SAMPLES_DEFAULT))
|
||||
group.add_argument("-s", "--samples", type=int, help=sample_help)
|
||||
|
||||
return parser
|
||||
|
||||
|
||||
def run_arg_parser(parser, need_id=False, no_stdout_errors=False):
|
||||
"""Run parse_args on a parser previously created with create_arg_parser
|
||||
|
||||
Args:
|
||||
need_id (bool): A flag to set in options to indicate whether or not to
|
||||
set dish_id on the global state object; see get_data for more
|
||||
detail.
|
||||
no_stdout_errors (bool): A flag set in options to protect stdout from
|
||||
error messages, in case that's where the data output is going, so
|
||||
may be being redirected to a file.
|
||||
|
||||
Returns:
|
||||
An argparse Namespace object with the parsed options set as attributes.
|
||||
"""
|
||||
all_modes = STATUS_MODES + HISTORY_STATS_MODES + UNGROUPED_MODES
|
||||
if parser.bulk_history:
|
||||
all_modes.append("bulk_history")
|
||||
parser.add_argument("mode",
|
||||
nargs="+",
|
||||
choices=all_modes,
|
||||
help="The data group to record, one or more of: " + ", ".join(all_modes),
|
||||
metavar="mode")
|
||||
|
||||
opts = parser.parse_args()
|
||||
|
||||
# for convenience, set flags for whether any mode in a group is selected
|
||||
opts.satus_mode = bool(set(STATUS_MODES).intersection(opts.mode))
|
||||
opts.history_stats_mode = bool(set(HISTORY_STATS_MODES).intersection(opts.mode))
|
||||
opts.bulk_mode = "bulk_history" in opts.mode
|
||||
|
||||
if opts.samples is None:
|
||||
opts.samples = -1 if opts.bulk_mode else int(
|
||||
opts.loop_interval) if opts.loop_interval >= 1.0 else SAMPLES_DEFAULT
|
||||
|
||||
opts.no_stdout_errors = no_stdout_errors
|
||||
opts.need_id = need_id
|
||||
|
||||
return opts
|
||||
|
||||
|
||||
def conn_error(opts, msg, *args):
|
||||
"""Indicate an error in an appropriate way."""
|
||||
# Connection errors that happen in an interval loop are not critical
|
||||
# failures, but are interesting enough to print in non-verbose mode.
|
||||
if opts.loop_interval > 0.0 and not opts.no_stdout_errors:
|
||||
print(msg % args)
|
||||
else:
|
||||
logging.error(msg, *args)
|
||||
|
||||
|
||||
class GlobalState:
|
||||
"""A class for keeping state across loop iterations."""
|
||||
def __init__(self):
|
||||
self.counter = None
|
||||
self.timestamp = None
|
||||
self.dish_id = None
|
||||
self.context = starlink_grpc.ChannelContext()
|
||||
|
||||
def shutdown(self):
|
||||
self.context.close()
|
||||
|
||||
|
||||
def get_data(opts, gstate, add_item, add_sequence, add_bulk=None):
|
||||
"""Fetch data from the dish, pull it apart and call back with the pieces.
|
||||
|
||||
This function uses call backs to return the useful data. If need_id is set
|
||||
in opts, then it is guaranteed that dish_id will have been set in gstate
|
||||
prior to any of the call backs being invoked.
|
||||
|
||||
Args:
|
||||
opts (object): The options object returned from run_arg_parser.
|
||||
gstate (GlobalState): An object for keeping track of state across
|
||||
multiple calls.
|
||||
add_item (function): Call back for non-sequence data, with prototype:
|
||||
|
||||
add_item(name, value, category)
|
||||
add_sequence (function): Call back for sequence data, with prototype:
|
||||
|
||||
add_sequence(name, value, category, start_index_label)
|
||||
add_bulk (function): Optional. Call back for bulk history data, with
|
||||
prototype:
|
||||
|
||||
add_bulk(bulk_data, count, start_timestamp, start_counter)
|
||||
|
||||
Returns:
|
||||
1 if there were any failures getting data from the dish, otherwise 0.
|
||||
"""
|
||||
def add_data(data, category):
|
||||
for key, val in data.items():
|
||||
name, start, seq = BRACKETS_RE.match(key).group(1, 4, 5)
|
||||
if seq is None:
|
||||
add_item(name, val, category)
|
||||
else:
|
||||
add_sequence(name, val, category, int(start) if start else 0)
|
||||
|
||||
if opts.satus_mode:
|
||||
try:
|
||||
groups = starlink_grpc.status_data(context=gstate.context)
|
||||
status_data, obstruct_detail, alert_detail = groups[0:3]
|
||||
except starlink_grpc.GrpcError as e:
|
||||
if "status" in opts.mode:
|
||||
if opts.need_id and gstate.dish_id is None:
|
||||
conn_error(opts, "Dish unreachable and ID unknown, so not recording state")
|
||||
else:
|
||||
if opts.verbose:
|
||||
print("Dish unreachable")
|
||||
if "status" in opts.mode:
|
||||
add_item("state", "DISH_UNREACHABLE", "status")
|
||||
return 0
|
||||
return 1
|
||||
if opts.need_id:
|
||||
gstate.dish_id = status_data["id"]
|
||||
del status_data["id"]
|
||||
if "status" in opts.mode:
|
||||
add_data(status_data, "status")
|
||||
if "obstruction_detail" in opts.mode:
|
||||
add_data(obstruct_detail, "status")
|
||||
if "alert_detail" in opts.mode:
|
||||
add_data(alert_detail, "status")
|
||||
elif opts.need_id and gstate.dish_id is None:
|
||||
try:
|
||||
gstate.dish_id = starlink_grpc.get_id(context=gstate.context)
|
||||
except starlink_grpc.GrpcError as e:
|
||||
conn_error(opts, "Failure getting dish ID: %s", str(e))
|
||||
return 1
|
||||
if opts.verbose:
|
||||
print("Using dish ID: " + gstate.dish_id)
|
||||
|
||||
if opts.history_stats_mode:
|
||||
try:
|
||||
groups = starlink_grpc.history_stats(opts.samples, opts.verbose, context=gstate.context)
|
||||
general, ping, runlen, latency, loaded, usage = groups[0:6]
|
||||
except starlink_grpc.GrpcError as e:
|
||||
conn_error(opts, "Failure getting ping stats: %s", str(e))
|
||||
return 1
|
||||
add_data(general, "ping_stats")
|
||||
if "ping_drop" in opts.mode:
|
||||
add_data(ping, "ping_stats")
|
||||
if "ping_run_length" in opts.mode:
|
||||
add_data(runlen, "ping_stats")
|
||||
if "ping_latency" in opts.mode:
|
||||
add_data(latency, "ping_stats")
|
||||
if "ping_loaded_latency" in opts.mode:
|
||||
add_data(loaded, "ping_stats")
|
||||
if "usage" in opts.mode:
|
||||
add_data(usage, "usage")
|
||||
|
||||
if opts.bulk_mode and add_bulk:
|
||||
return get_bulk_data(opts, gstate, add_bulk)
|
||||
|
||||
return 0
|
||||
|
||||
|
||||
def get_bulk_data(opts, gstate, add_bulk):
|
||||
"""Fetch bulk data. See `get_data` for details.
|
||||
|
||||
This was split out in case bulk data needs to be handled separately, for
|
||||
example, if dish_id needs to be known before calling.
|
||||
"""
|
||||
before = time.time()
|
||||
|
||||
start = gstate.counter
|
||||
parse_samples = opts.samples if start is None else -1
|
||||
try:
|
||||
general, bulk = starlink_grpc.history_bulk_data(parse_samples,
|
||||
start=start,
|
||||
verbose=opts.verbose,
|
||||
context=gstate.context)
|
||||
except starlink_grpc.GrpcError as e:
|
||||
conn_error(opts, "Failure getting history: %s", str(e))
|
||||
return 1
|
||||
|
||||
after = time.time()
|
||||
parsed_samples = general["samples"]
|
||||
new_counter = general["end_counter"]
|
||||
timestamp = gstate.timestamp
|
||||
# check this first, so it doesn't report as lost time sync
|
||||
if gstate.counter is not None and new_counter != gstate.counter + parsed_samples:
|
||||
timestamp = None
|
||||
# Allow up to 2 seconds of time drift before forcibly re-syncing, since
|
||||
# +/- 1 second can happen just due to scheduler timing.
|
||||
if timestamp is not None and not before - 2.0 <= timestamp + parsed_samples <= after + 2.0:
|
||||
if opts.verbose:
|
||||
print("Lost sample time sync at: " +
|
||||
str(datetime.fromtimestamp(timestamp + parsed_samples, tz=timezone.utc)))
|
||||
timestamp = None
|
||||
if timestamp is None:
|
||||
timestamp = int(before)
|
||||
if opts.verbose:
|
||||
print("Establishing new time base: {0} -> {1}".format(
|
||||
new_counter, datetime.fromtimestamp(timestamp, tz=timezone.utc)))
|
||||
timestamp -= parsed_samples
|
||||
|
||||
add_bulk(bulk, parsed_samples, timestamp, new_counter - parsed_samples)
|
||||
|
||||
gstate.counter = new_counter
|
||||
gstate.timestamp = timestamp + parsed_samples
|
||||
322
dish_grpc_influx.py
Normal file
322
dish_grpc_influx.py
Normal file
|
|
@ -0,0 +1,322 @@
|
|||
#!/usr/bin/python3
|
||||
"""Write Starlink user terminal data to an InfluxDB database.
|
||||
|
||||
This script pulls the current status info and/or metrics computed from the
|
||||
history data and writes them to the specified InfluxDB database either once
|
||||
or in a periodic loop.
|
||||
|
||||
NOTE: The Starlink user terminal does not include time values with its
|
||||
history or status data, so this script uses current system time to compute
|
||||
the timestamps it sends to InfluxDB. It is recommended to run this script on
|
||||
a host that has its system clock synced via NTP. Otherwise, the timestamps
|
||||
may get out of sync with real time.
|
||||
"""
|
||||
|
||||
from datetime import datetime
|
||||
from datetime import timezone
|
||||
import logging
|
||||
import os
|
||||
import signal
|
||||
import sys
|
||||
import time
|
||||
import warnings
|
||||
|
||||
from influxdb import InfluxDBClient
|
||||
|
||||
import dish_common
|
||||
|
||||
HOST_DEFAULT = "localhost"
|
||||
DATABASE_DEFAULT = "starlinkstats"
|
||||
BULK_MEASUREMENT = "spacex.starlink.user_terminal.history"
|
||||
FLUSH_LIMIT = 6
|
||||
MAX_BATCH = 5000
|
||||
MAX_QUEUE_LENGTH = 864000
|
||||
|
||||
|
||||
class Terminated(Exception):
|
||||
pass
|
||||
|
||||
|
||||
def handle_sigterm(signum, frame):
|
||||
# Turn SIGTERM into an exception so main loop can clean up
|
||||
raise Terminated
|
||||
|
||||
|
||||
def parse_args():
|
||||
parser = dish_common.create_arg_parser(output_description="write it to an InfluxDB database")
|
||||
|
||||
group = parser.add_argument_group(title="InfluxDB database options")
|
||||
group.add_argument("-n",
|
||||
"--hostname",
|
||||
default=HOST_DEFAULT,
|
||||
dest="host",
|
||||
help="Hostname of MQTT broker, default: " + HOST_DEFAULT)
|
||||
group.add_argument("-p", "--port", type=int, help="Port number to use on MQTT broker")
|
||||
group.add_argument("-P", "--password", help="Set password for username/password authentication")
|
||||
group.add_argument("-U", "--username", help="Set username for authentication")
|
||||
group.add_argument("-D",
|
||||
"--database",
|
||||
default=DATABASE_DEFAULT,
|
||||
help="Database name to use, default: " + DATABASE_DEFAULT)
|
||||
group.add_argument("-R", "--retention-policy", help="Retention policy name to use")
|
||||
group.add_argument("-k",
|
||||
"--skip-query",
|
||||
action="store_true",
|
||||
help="Skip querying for prior sample write point in bulk mode")
|
||||
group.add_argument("-C",
|
||||
"--ca-cert",
|
||||
dest="verify_ssl",
|
||||
help="Enable SSL/TLS using specified CA cert to verify broker",
|
||||
metavar="FILENAME")
|
||||
group.add_argument("-I",
|
||||
"--insecure",
|
||||
action="store_false",
|
||||
dest="verify_ssl",
|
||||
help="Enable SSL/TLS but disable certificate verification (INSECURE!)")
|
||||
group.add_argument("-S",
|
||||
"--secure",
|
||||
action="store_true",
|
||||
dest="verify_ssl",
|
||||
help="Enable SSL/TLS using default CA cert")
|
||||
|
||||
env_map = (
|
||||
("INFLUXDB_HOST", "host"),
|
||||
("INFLUXDB_PORT", "port"),
|
||||
("INFLUXDB_USER", "username"),
|
||||
("INFLUXDB_PWD", "password"),
|
||||
("INFLUXDB_DB", "database"),
|
||||
("INFLUXDB_RP", "retention-policy"),
|
||||
("INFLUXDB_SSL", "verify_ssl"),
|
||||
)
|
||||
env_defaults = {}
|
||||
for var, opt in env_map:
|
||||
# check both set and not empty string
|
||||
val = os.environ.get(var)
|
||||
if val:
|
||||
if var == "INFLUXDB_SSL" and val == "secure":
|
||||
env_defaults[opt] = True
|
||||
elif var == "INFLUXDB_SSL" and val == "insecure":
|
||||
env_defaults[opt] = False
|
||||
else:
|
||||
env_defaults[opt] = val
|
||||
parser.set_defaults(**env_defaults)
|
||||
|
||||
opts = dish_common.run_arg_parser(parser, need_id=True)
|
||||
|
||||
if opts.username is None and opts.password is not None:
|
||||
parser.error("Password authentication requires username to be set")
|
||||
|
||||
opts.icargs = {"timeout": 5}
|
||||
for key in ["port", "host", "password", "username", "database", "verify_ssl"]:
|
||||
val = getattr(opts, key)
|
||||
if val is not None:
|
||||
opts.icargs[key] = val
|
||||
|
||||
if opts.verify_ssl is not None:
|
||||
opts.icargs["ssl"] = True
|
||||
|
||||
return opts
|
||||
|
||||
|
||||
def flush_points(opts, gstate):
|
||||
try:
|
||||
while len(gstate.points) > MAX_BATCH:
|
||||
gstate.influx_client.write_points(gstate.points[:MAX_BATCH],
|
||||
time_precision="s",
|
||||
retention_policy=opts.retention_policy)
|
||||
if opts.verbose:
|
||||
print("Data points written: " + str(MAX_BATCH))
|
||||
del gstate.points[:MAX_BATCH]
|
||||
if gstate.points:
|
||||
gstate.influx_client.write_points(gstate.points,
|
||||
time_precision="s",
|
||||
retention_policy=opts.retention_policy)
|
||||
if opts.verbose:
|
||||
print("Data points written: " + str(len(gstate.points)))
|
||||
gstate.points.clear()
|
||||
except Exception as e:
|
||||
dish_common.conn_error(opts, "Failed writing to InfluxDB database: %s", str(e))
|
||||
# If failures persist, don't just use infinite memory. Max queue
|
||||
# is currently 10 days of bulk data, so something is very wrong
|
||||
# if it's ever exceeded.
|
||||
if len(gstate.points) > MAX_QUEUE_LENGTH:
|
||||
logging.error("Max write queue exceeded, discarding data.")
|
||||
del gstate.points[:-MAX_QUEUE_LENGTH]
|
||||
return 1
|
||||
|
||||
return 0
|
||||
|
||||
|
||||
def query_counter(gstate, start, end):
|
||||
try:
|
||||
# fetch the latest point where counter field was recorded
|
||||
result = gstate.influx_client.query("SELECT counter FROM \"{0}\" "
|
||||
"WHERE time>={1}s AND time<{2}s AND id=$id "
|
||||
"ORDER by time DESC LIMIT 1;".format(
|
||||
BULK_MEASUREMENT, start, end),
|
||||
bind_params={"id": gstate.dish_id},
|
||||
epoch="s")
|
||||
points = list(result.get_points())
|
||||
if points:
|
||||
counter = points[0].get("counter", None)
|
||||
timestamp = points[0].get("time", 0)
|
||||
if counter and timestamp:
|
||||
return int(counter), int(timestamp)
|
||||
except TypeError as e:
|
||||
# bind_params was added in influxdb-python v5.2.3. That would be easy
|
||||
# enough to work around, but older versions had other problems with
|
||||
# query(), so just skip this functionality.
|
||||
logging.error(
|
||||
"Failed running query, probably due to influxdb-python version too old. "
|
||||
"Skipping resumption from prior counter value. Reported error was: %s", str(e))
|
||||
|
||||
return None, 0
|
||||
|
||||
|
||||
def sync_timebase(opts, gstate):
|
||||
try:
|
||||
db_counter, db_timestamp = query_counter(gstate, gstate.start_timestamp, gstate.timestamp)
|
||||
except Exception as e:
|
||||
# could be temporary outage, so try again next time
|
||||
dish_common.conn_error(opts, "Failed querying InfluxDB for prior count: %s", str(e))
|
||||
return
|
||||
gstate.timebase_synced = True
|
||||
|
||||
if db_counter and gstate.start_counter <= db_counter:
|
||||
del gstate.deferred_points[:db_counter - gstate.start_counter]
|
||||
if gstate.deferred_points:
|
||||
delta_timestamp = db_timestamp - (gstate.deferred_points[0]["time"] - 1)
|
||||
# to prevent +/- 1 second timestamp drift when the script restarts,
|
||||
# if time base is within 2 seconds of that of the last sample in
|
||||
# the database, correct back to that time base
|
||||
if delta_timestamp == 0:
|
||||
if opts.verbose:
|
||||
print("Exactly synced with database time base")
|
||||
elif -2 <= delta_timestamp <= 2:
|
||||
if opts.verbose:
|
||||
print("Replacing with existing time base: {0} -> {1}".format(
|
||||
db_counter, datetime.fromtimestamp(db_timestamp, tz=timezone.utc)))
|
||||
for point in gstate.deferred_points:
|
||||
db_timestamp += 1
|
||||
if point["time"] + delta_timestamp == db_timestamp:
|
||||
point["time"] = db_timestamp
|
||||
else:
|
||||
# lost time sync when recording data, leave the rest
|
||||
break
|
||||
else:
|
||||
gstate.timestamp = db_timestamp
|
||||
else:
|
||||
if opts.verbose:
|
||||
print("Database time base out of sync by {0} seconds".format(delta_timestamp))
|
||||
|
||||
gstate.points.extend(gstate.deferred_points)
|
||||
gstate.deferred_points.clear()
|
||||
|
||||
|
||||
def loop_body(opts, gstate):
|
||||
fields = {"status": {}, "ping_stats": {}, "usage": {}}
|
||||
|
||||
def cb_add_item(key, val, category):
|
||||
fields[category][key] = val
|
||||
|
||||
def cb_add_sequence(key, val, category, start):
|
||||
for i, subval in enumerate(val, start=start):
|
||||
fields[category]["{0}_{1}".format(key, i)] = subval
|
||||
|
||||
def cb_add_bulk(bulk, count, timestamp, counter):
|
||||
if gstate.start_timestamp is None:
|
||||
gstate.start_timestamp = timestamp
|
||||
gstate.start_counter = counter
|
||||
points = gstate.points if gstate.timebase_synced else gstate.deferred_points
|
||||
for i in range(count):
|
||||
timestamp += 1
|
||||
points.append({
|
||||
"measurement": BULK_MEASUREMENT,
|
||||
"tags": {
|
||||
"id": gstate.dish_id
|
||||
},
|
||||
"time": timestamp,
|
||||
"fields": {key: val[i] for key, val in bulk.items() if val[i] is not None},
|
||||
})
|
||||
if points:
|
||||
# save off counter value for script restart
|
||||
points[-1]["fields"]["counter"] = counter + count
|
||||
|
||||
now = time.time()
|
||||
rc = dish_common.get_data(opts, gstate, cb_add_item, cb_add_sequence, add_bulk=cb_add_bulk)
|
||||
if rc:
|
||||
return rc
|
||||
|
||||
for category in fields:
|
||||
if fields[category]:
|
||||
gstate.points.append({
|
||||
"measurement": "spacex.starlink.user_terminal." + category,
|
||||
"tags": {
|
||||
"id": gstate.dish_id
|
||||
},
|
||||
"time": int(now),
|
||||
"fields": fields[category],
|
||||
})
|
||||
|
||||
# This is here and not before the points being processed because if the
|
||||
# query previously failed, there will be points that were processed in
|
||||
# a prior loop. This avoids having to handle that as a special case.
|
||||
if opts.bulk_mode and not gstate.timebase_synced:
|
||||
sync_timebase(opts, gstate)
|
||||
|
||||
if opts.verbose:
|
||||
print("Data points queued: " + str(len(gstate.points)))
|
||||
|
||||
if len(gstate.points) >= FLUSH_LIMIT:
|
||||
return flush_points(opts, gstate)
|
||||
|
||||
return 0
|
||||
|
||||
|
||||
def main():
|
||||
opts = parse_args()
|
||||
|
||||
logging.basicConfig(format="%(levelname)s: %(message)s")
|
||||
|
||||
gstate = dish_common.GlobalState()
|
||||
gstate.points = []
|
||||
gstate.deferred_points = []
|
||||
gstate.timebase_synced = opts.skip_query
|
||||
gstate.start_timestamp = None
|
||||
gstate.start_counter = None
|
||||
|
||||
if "verify_ssl" in opts.icargs and not opts.icargs["verify_ssl"]:
|
||||
# user has explicitly said be insecure, so don't warn about it
|
||||
warnings.filterwarnings("ignore", message="Unverified HTTPS request")
|
||||
|
||||
signal.signal(signal.SIGTERM, handle_sigterm)
|
||||
try:
|
||||
# attempt to hack around breakage between influxdb-python client and 2.0 server:
|
||||
gstate.influx_client = InfluxDBClient(**opts.icargs, headers={"Accept": "application/json"})
|
||||
except TypeError:
|
||||
# ...unless influxdb-python package version is too old
|
||||
gstate.influx_client = InfluxDBClient(**opts.icargs)
|
||||
|
||||
try:
|
||||
next_loop = time.monotonic()
|
||||
while True:
|
||||
rc = loop_body(opts, gstate)
|
||||
if opts.loop_interval > 0.0:
|
||||
now = time.monotonic()
|
||||
next_loop = max(next_loop + opts.loop_interval, now)
|
||||
time.sleep(next_loop - now)
|
||||
else:
|
||||
break
|
||||
except Terminated:
|
||||
pass
|
||||
finally:
|
||||
if gstate.points:
|
||||
rc = flush_points(opts, gstate)
|
||||
gstate.influx_client.close()
|
||||
gstate.shutdown()
|
||||
|
||||
sys.exit(rc)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
133
dish_grpc_mqtt.py
Normal file
133
dish_grpc_mqtt.py
Normal file
|
|
@ -0,0 +1,133 @@
|
|||
#!/usr/bin/python3
|
||||
"""Publish Starlink user terminal data to a MQTT broker.
|
||||
|
||||
This script pulls the current status info and/or metrics computed from the
|
||||
history data and publishes them to the specified MQTT broker either once or
|
||||
in a periodic loop.
|
||||
"""
|
||||
|
||||
import logging
|
||||
import sys
|
||||
import time
|
||||
|
||||
try:
|
||||
import ssl
|
||||
ssl_ok = True
|
||||
except ImportError:
|
||||
ssl_ok = False
|
||||
|
||||
import paho.mqtt.publish
|
||||
|
||||
import dish_common
|
||||
|
||||
HOST_DEFAULT = "localhost"
|
||||
|
||||
|
||||
def parse_args():
|
||||
parser = dish_common.create_arg_parser(output_description="publish it to a MQTT broker",
|
||||
bulk_history=False)
|
||||
|
||||
group = parser.add_argument_group(title="MQTT broker options")
|
||||
group.add_argument("-n",
|
||||
"--hostname",
|
||||
default=HOST_DEFAULT,
|
||||
help="Hostname of MQTT broker, default: " + HOST_DEFAULT)
|
||||
group.add_argument("-p", "--port", type=int, help="Port number to use on MQTT broker")
|
||||
group.add_argument("-P", "--password", help="Set password for username/password authentication")
|
||||
group.add_argument("-U", "--username", help="Set username for authentication")
|
||||
if ssl_ok:
|
||||
|
||||
def wrap_ca_arg(arg):
|
||||
return {"ca_certs": arg}
|
||||
|
||||
group.add_argument("-C",
|
||||
"--ca-cert",
|
||||
type=wrap_ca_arg,
|
||||
dest="tls",
|
||||
help="Enable SSL/TLS using specified CA cert to verify broker",
|
||||
metavar="FILENAME")
|
||||
group.add_argument("-I",
|
||||
"--insecure",
|
||||
action="store_const",
|
||||
const={"cert_reqs": ssl.CERT_NONE},
|
||||
dest="tls",
|
||||
help="Enable SSL/TLS but disable certificate verification (INSECURE!)")
|
||||
group.add_argument("-S",
|
||||
"--secure",
|
||||
action="store_const",
|
||||
const={},
|
||||
dest="tls",
|
||||
help="Enable SSL/TLS using default CA cert")
|
||||
else:
|
||||
parser.epilog += "\nSSL support options not available due to missing ssl module"
|
||||
|
||||
opts = dish_common.run_arg_parser(parser, need_id=True)
|
||||
|
||||
if opts.username is None and opts.password is not None:
|
||||
parser.error("Password authentication requires username to be set")
|
||||
|
||||
opts.mqargs = {}
|
||||
for key in ["hostname", "port", "tls"]:
|
||||
val = getattr(opts, key)
|
||||
if val is not None:
|
||||
opts.mqargs[key] = val
|
||||
|
||||
if opts.username is not None:
|
||||
opts.mqargs["auth"] = {"username": opts.username}
|
||||
if opts.password is not None:
|
||||
opts.mqargs["auth"]["password"] = opts.password
|
||||
|
||||
return opts
|
||||
|
||||
|
||||
def loop_body(opts, gstate):
|
||||
msgs = []
|
||||
|
||||
def cb_add_item(key, val, category):
|
||||
msgs.append(("starlink/dish_{0}/{1}/{2}".format(category, gstate.dish_id,
|
||||
key), val, 0, False))
|
||||
|
||||
def cb_add_sequence(key, val, category, _):
|
||||
msgs.append(
|
||||
("starlink/dish_{0}/{1}/{2}".format(category, gstate.dish_id,
|
||||
key), ",".join(str(x) for x in val), 0, False))
|
||||
|
||||
rc = dish_common.get_data(opts, gstate, cb_add_item, cb_add_sequence)
|
||||
|
||||
if msgs:
|
||||
try:
|
||||
paho.mqtt.publish.multiple(msgs, client_id=gstate.dish_id, **opts.mqargs)
|
||||
if opts.verbose:
|
||||
print("Successfully published to MQTT broker")
|
||||
except Exception as e:
|
||||
dish_common.conn_error(opts, "Failed publishing to MQTT broker: %s", str(e))
|
||||
rc = 1
|
||||
|
||||
return rc
|
||||
|
||||
|
||||
def main():
|
||||
opts = parse_args()
|
||||
|
||||
logging.basicConfig(format="%(levelname)s: %(message)s")
|
||||
|
||||
gstate = dish_common.GlobalState()
|
||||
|
||||
try:
|
||||
next_loop = time.monotonic()
|
||||
while True:
|
||||
rc = loop_body(opts, gstate)
|
||||
if opts.loop_interval > 0.0:
|
||||
now = time.monotonic()
|
||||
next_loop = max(next_loop + opts.loop_interval, now)
|
||||
time.sleep(next_loop - now)
|
||||
else:
|
||||
break
|
||||
finally:
|
||||
gstate.shutdown()
|
||||
|
||||
sys.exit(rc)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
243
dish_grpc_sqlite.py
Normal file
243
dish_grpc_sqlite.py
Normal file
|
|
@ -0,0 +1,243 @@
|
|||
#!/usr/bin/python3
|
||||
"""Write Starlink user terminal data to a sqlite database.
|
||||
|
||||
This script pulls the current status info and/or metrics computed from the
|
||||
history data and writes them to the specified sqlite database either once or
|
||||
in a periodic loop.
|
||||
|
||||
Array data is currently written to the database as text strings of comma-
|
||||
separated values, which may not be the best method for some use cases. If you
|
||||
find yourself wishing they were handled better, please open a feature request
|
||||
at https://github.com/sparky8512/starlink-grpc-tools/issues explaining the use
|
||||
case and how you would rather see it. This only affects a few fields, since
|
||||
most of the useful data is not in arrays.
|
||||
|
||||
NOTE: The Starlink user terminal does not include time values with its
|
||||
history or status data, so this script uses current system time to compute
|
||||
the timestamps it writes into the database. It is recommended to run this
|
||||
script on a host that has its system clock synced via NTP. Otherwise, the
|
||||
timestamps may get out of sync with real time.
|
||||
"""
|
||||
|
||||
from datetime import datetime
|
||||
from datetime import timezone
|
||||
from itertools import repeat
|
||||
import logging
|
||||
import signal
|
||||
import sqlite3
|
||||
import sys
|
||||
import time
|
||||
|
||||
import dish_common
|
||||
import starlink_grpc
|
||||
|
||||
SCHEMA_VERSION = 1
|
||||
|
||||
|
||||
class Terminated(Exception):
|
||||
pass
|
||||
|
||||
|
||||
def handle_sigterm(signum, frame):
|
||||
# Turn SIGTERM into an exception so main loop can clean up
|
||||
raise Terminated
|
||||
|
||||
|
||||
def parse_args():
|
||||
parser = dish_common.create_arg_parser(output_description="write it to a sqlite database")
|
||||
|
||||
parser.add_argument("database", help="Database file to use")
|
||||
|
||||
group = parser.add_argument_group(title="sqlite database options")
|
||||
group.add_argument("-k",
|
||||
"--skip-query",
|
||||
action="store_true",
|
||||
help="Skip querying for prior sample write point in bulk mode")
|
||||
|
||||
opts = dish_common.run_arg_parser(parser, need_id=True)
|
||||
|
||||
return opts
|
||||
|
||||
|
||||
def query_counter(opts, gstate):
|
||||
now = time.time()
|
||||
cur = gstate.sql_conn.cursor()
|
||||
cur.execute(
|
||||
'SELECT "time", "counter" FROM "history" WHERE "time"<? AND "id"=? '
|
||||
'ORDER BY "time" DESC LIMIT 1', (now, gstate.dish_id))
|
||||
row = cur.fetchone()
|
||||
cur.close()
|
||||
|
||||
if row and row[0] and row[1]:
|
||||
if opts.verbose:
|
||||
print("Existing time base: {0} -> {1}".format(
|
||||
row[1], datetime.fromtimestamp(row[0], tz=timezone.utc)))
|
||||
return row
|
||||
else:
|
||||
return 0, None
|
||||
|
||||
|
||||
def loop_body(opts, gstate):
|
||||
tables = {"status": {}, "ping_stats": {}, "usage": {}}
|
||||
hist_cols = ["time", "id"]
|
||||
hist_rows = []
|
||||
|
||||
def cb_add_item(key, val, category):
|
||||
tables[category][key] = val
|
||||
|
||||
def cb_add_sequence(key, val, category, start):
|
||||
tables[category][key] = ",".join(str(subv) if subv is not None else "" for subv in val)
|
||||
|
||||
def cb_add_bulk(bulk, count, timestamp, counter):
|
||||
nonlocal hist_cols
|
||||
if len(hist_cols) == 2:
|
||||
hist_cols.extend(bulk.keys())
|
||||
hist_cols.append("counter")
|
||||
for i in range(count):
|
||||
timestamp += 1
|
||||
counter += 1
|
||||
row = [timestamp, gstate.dish_id]
|
||||
row.extend(val[i] for val in bulk.values())
|
||||
row.append(counter)
|
||||
hist_rows.append(row)
|
||||
|
||||
now = int(time.time())
|
||||
rc = dish_common.get_data(opts, gstate, cb_add_item, cb_add_sequence)
|
||||
|
||||
if opts.bulk_mode and not rc:
|
||||
if gstate.counter is None and opts.samples < 0:
|
||||
gstate.timestamp, gstate.counter = query_counter(opts, gstate)
|
||||
rc = dish_common.get_bulk_data(opts, gstate, cb_add_bulk)
|
||||
|
||||
rows_written = 0
|
||||
|
||||
try:
|
||||
cur = gstate.sql_conn.cursor()
|
||||
for category, fields in tables.items():
|
||||
if fields:
|
||||
sql = 'INSERT OR REPLACE INTO "{0}" ("time","id",{1}) VALUES ({2})'.format(
|
||||
category, ",".join('"' + x + '"' for x in fields),
|
||||
",".join(repeat("?",
|
||||
len(fields) + 2)))
|
||||
values = [now, gstate.dish_id]
|
||||
values.extend(fields.values())
|
||||
cur.execute(sql, values)
|
||||
rows_written += 1
|
||||
|
||||
if hist_rows:
|
||||
sql = 'INSERT OR REPLACE INTO "history" ({0}) VALUES({1})'.format(
|
||||
",".join('"' + x + '"' for x in hist_cols), ",".join(repeat("?", len(hist_cols))))
|
||||
cur.executemany(sql, hist_rows)
|
||||
rows_written += len(hist_rows)
|
||||
|
||||
cur.close()
|
||||
gstate.sql_conn.commit()
|
||||
except sqlite3.OperationalError as e:
|
||||
# these are not necessarily fatal, but also not much can do about
|
||||
logging.error("Unexpected error from database, discarding %s rows: %s", rows_written, e)
|
||||
rc = 1
|
||||
else:
|
||||
if opts.verbose:
|
||||
print("Rows written to db:", rows_written)
|
||||
|
||||
return rc
|
||||
|
||||
|
||||
def ensure_schema(opts, conn):
|
||||
cur = conn.cursor()
|
||||
cur.execute("PRAGMA user_version")
|
||||
version = cur.fetchone()
|
||||
if version and version[0] == SCHEMA_VERSION:
|
||||
cur.close()
|
||||
return
|
||||
|
||||
if opts.verbose:
|
||||
if version[0]:
|
||||
print("Upgrading schema from version:", version)
|
||||
else:
|
||||
print("Initializing new database")
|
||||
|
||||
# If/when more fields get added or changed, the schema will have changed
|
||||
# and this will have to handle the upgrade case. For now, just create the
|
||||
# new tables.
|
||||
|
||||
tables = {}
|
||||
name_groups = starlink_grpc.status_field_names()
|
||||
type_groups = starlink_grpc.status_field_types()
|
||||
tables["status"] = zip(name_groups, type_groups)
|
||||
|
||||
name_groups = starlink_grpc.history_stats_field_names()
|
||||
type_groups = starlink_grpc.history_stats_field_types()
|
||||
tables["ping_stats"] = zip(name_groups[0:5], type_groups[0:5])
|
||||
tables["usage"] = ((name_groups[5], type_groups[5]),)
|
||||
|
||||
name_groups = starlink_grpc.history_bulk_field_names()
|
||||
type_groups = starlink_grpc.history_bulk_field_types()
|
||||
tables["history"] = ((name_groups[1], type_groups[1]), (["counter"], [int]))
|
||||
|
||||
def sql_type(type_class):
|
||||
if issubclass(type_class, float):
|
||||
return "REAL"
|
||||
if issubclass(type_class, bool):
|
||||
# advisory only, stores as int:
|
||||
return "BOOLEAN"
|
||||
if issubclass(type_class, int):
|
||||
return "INTEGER"
|
||||
if issubclass(type_class, str):
|
||||
return "TEXT"
|
||||
raise TypeError
|
||||
|
||||
for table, group_pairs in tables.items():
|
||||
columns = ['"time" INTEGER NOT NULL', '"id" TEXT NOT NULL']
|
||||
for name_group, type_group in group_pairs:
|
||||
for name_item, type_item in zip(name_group, type_group):
|
||||
name_item = dish_common.BRACKETS_RE.match(name_item).group(1)
|
||||
if name_item != "id":
|
||||
columns.append('"{0}" {1}'.format(name_item, sql_type(type_item)))
|
||||
sql = 'CREATE TABLE "{0}" ({1}, PRIMARY KEY("time","id"))'.format(table, ", ".join(columns))
|
||||
cur.execute(sql)
|
||||
|
||||
cur.execute("PRAGMA user_version={0}".format(SCHEMA_VERSION))
|
||||
|
||||
cur.close()
|
||||
conn.commit()
|
||||
|
||||
|
||||
def main():
|
||||
opts = parse_args()
|
||||
|
||||
logging.basicConfig(format="%(levelname)s: %(message)s")
|
||||
|
||||
gstate = dish_common.GlobalState()
|
||||
gstate.points = []
|
||||
gstate.deferred_points = []
|
||||
|
||||
signal.signal(signal.SIGTERM, handle_sigterm)
|
||||
gstate.sql_conn = sqlite3.connect(opts.database)
|
||||
ensure_schema(opts, gstate.sql_conn)
|
||||
|
||||
rc = 0
|
||||
try:
|
||||
next_loop = time.monotonic()
|
||||
while True:
|
||||
rc = loop_body(opts, gstate)
|
||||
if opts.loop_interval > 0.0:
|
||||
now = time.monotonic()
|
||||
next_loop = max(next_loop + opts.loop_interval, now)
|
||||
time.sleep(next_loop - now)
|
||||
else:
|
||||
break
|
||||
except sqlite3.Error as e:
|
||||
logging.error("Database error: %s", e)
|
||||
rc = 1
|
||||
except Terminated:
|
||||
pass
|
||||
finally:
|
||||
gstate.sql_conn.close()
|
||||
gstate.shutdown()
|
||||
|
||||
sys.exit(rc)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
205
dish_grpc_text.py
Normal file
205
dish_grpc_text.py
Normal file
|
|
@ -0,0 +1,205 @@
|
|||
#!/usr/bin/python3
|
||||
"""Output Starlink user terminal data info in text format.
|
||||
|
||||
This script pulls the current status info and/or metrics computed from the
|
||||
history data and prints them to stdout either once or in a periodic loop.
|
||||
By default, it will print the results in CSV format.
|
||||
"""
|
||||
|
||||
from datetime import datetime
|
||||
import logging
|
||||
import sys
|
||||
import time
|
||||
|
||||
import dish_common
|
||||
import starlink_grpc
|
||||
|
||||
VERBOSE_FIELD_MAP = {
|
||||
# status fields (the remainder are either self-explanatory or I don't
|
||||
# know with confidence what they mean)
|
||||
"alerts": "Alerts bit field",
|
||||
|
||||
# ping_drop fields
|
||||
"samples": "Parsed samples",
|
||||
"end_counter": "Sample counter",
|
||||
"total_ping_drop": "Total ping drop",
|
||||
"count_full_ping_drop": "Count of drop == 1",
|
||||
"count_obstructed": "Obstructed",
|
||||
"total_obstructed_ping_drop": "Obstructed ping drop",
|
||||
"count_full_obstructed_ping_drop": "Obstructed drop == 1",
|
||||
"count_unscheduled": "Unscheduled",
|
||||
"total_unscheduled_ping_drop": "Unscheduled ping drop",
|
||||
"count_full_unscheduled_ping_drop": "Unscheduled drop == 1",
|
||||
|
||||
# ping_run_length fields
|
||||
"init_run_fragment": "Initial drop run fragment",
|
||||
"final_run_fragment": "Final drop run fragment",
|
||||
"run_seconds": "Per-second drop runs",
|
||||
"run_minutes": "Per-minute drop runs",
|
||||
|
||||
# ping_latency fields
|
||||
"mean_all_ping_latency": "Mean RTT, drop < 1",
|
||||
"deciles_all_ping_latency": "RTT deciles, drop < 1",
|
||||
"mean_full_ping_latency": "Mean RTT, drop == 0",
|
||||
"deciles_full_ping_latency": "RTT deciles, drop == 0",
|
||||
"stdev_full_ping_latency": "RTT standard deviation, drop == 0",
|
||||
|
||||
# ping_loaded_latency is still experimental, so leave those unexplained
|
||||
|
||||
# usage fields
|
||||
"download_usage": "Bytes downloaded",
|
||||
"upload_usage": "Bytes uploaded",
|
||||
}
|
||||
|
||||
|
||||
def parse_args():
|
||||
parser = dish_common.create_arg_parser(
|
||||
output_description=
|
||||
"print it to standard output in text format; by default, will print in CSV format")
|
||||
|
||||
group = parser.add_argument_group(title="CSV output options")
|
||||
group.add_argument("-H",
|
||||
"--print-header",
|
||||
action="store_true",
|
||||
help="Print CSV header instead of parsing data")
|
||||
|
||||
opts = dish_common.run_arg_parser(parser, no_stdout_errors=True)
|
||||
|
||||
if len(opts.mode) > 1 and "bulk_history" in opts.mode:
|
||||
parser.error("bulk_history cannot be combined with other modes for CSV output")
|
||||
|
||||
return opts
|
||||
|
||||
|
||||
def print_header(opts):
|
||||
header = ["datetimestamp_utc"]
|
||||
|
||||
def header_add(names):
|
||||
for name in names:
|
||||
name, start, end = dish_common.BRACKETS_RE.match(name).group(1, 4, 5)
|
||||
if start:
|
||||
header.extend(name + "_" + str(x) for x in range(int(start), int(end)))
|
||||
elif end:
|
||||
header.extend(name + "_" + str(x) for x in range(int(end)))
|
||||
else:
|
||||
header.append(name)
|
||||
|
||||
if opts.satus_mode:
|
||||
status_names, obstruct_names, alert_names = starlink_grpc.status_field_names()
|
||||
if "status" in opts.mode:
|
||||
header_add(status_names)
|
||||
if "obstruction_detail" in opts.mode:
|
||||
header_add(obstruct_names)
|
||||
if "alert_detail" in opts.mode:
|
||||
header_add(alert_names)
|
||||
|
||||
if opts.bulk_mode:
|
||||
general, bulk = starlink_grpc.history_bulk_field_names()
|
||||
header_add(general)
|
||||
header_add(bulk)
|
||||
|
||||
if opts.history_stats_mode:
|
||||
groups = starlink_grpc.history_stats_field_names()
|
||||
general, ping, runlen, latency, loaded, usage = groups[0:6]
|
||||
header_add(general)
|
||||
if "ping_drop" in opts.mode:
|
||||
header_add(ping)
|
||||
if "ping_run_length" in opts.mode:
|
||||
header_add(runlen)
|
||||
if "ping_loaded_latency" in opts.mode:
|
||||
header_add(loaded)
|
||||
if "ping_latency" in opts.mode:
|
||||
header_add(latency)
|
||||
if "usage" in opts.mode:
|
||||
header_add(usage)
|
||||
|
||||
print(",".join(header))
|
||||
|
||||
|
||||
def loop_body(opts, gstate):
|
||||
if opts.verbose:
|
||||
csv_data = []
|
||||
else:
|
||||
csv_data = [datetime.utcnow().replace(microsecond=0).isoformat()]
|
||||
|
||||
def cb_data_add_item(name, val, category):
|
||||
if opts.verbose:
|
||||
csv_data.append("{0:22} {1}".format(VERBOSE_FIELD_MAP.get(name, name) + ":", val))
|
||||
else:
|
||||
# special case for get_status failure: this will be the lone item added
|
||||
if name == "state" and val == "DISH_UNREACHABLE":
|
||||
csv_data.extend(["", "", "", val])
|
||||
else:
|
||||
csv_data.append(str(val))
|
||||
|
||||
def cb_data_add_sequence(name, val, category, start):
|
||||
if opts.verbose:
|
||||
csv_data.append("{0:22} {1}".format(
|
||||
VERBOSE_FIELD_MAP.get(name, name) + ":", ", ".join(str(subval) for subval in val)))
|
||||
else:
|
||||
csv_data.extend(str(subval) for subval in val)
|
||||
|
||||
def cb_add_bulk(bulk, count, timestamp, counter):
|
||||
if opts.verbose:
|
||||
print("Time range (UTC): {0} -> {1}".format(
|
||||
datetime.fromtimestamp(timestamp).isoformat(),
|
||||
datetime.fromtimestamp(timestamp + count).isoformat()))
|
||||
for key, val in bulk.items():
|
||||
print("{0:22} {1}".format(key + ":", ", ".join(str(subval) for subval in val)))
|
||||
if opts.loop_interval > 0.0:
|
||||
print()
|
||||
else:
|
||||
for i in range(count):
|
||||
timestamp += 1
|
||||
fields = [datetime.fromtimestamp(timestamp).isoformat()]
|
||||
fields.extend(["" if val[i] is None else str(val[i]) for val in bulk.values()])
|
||||
print(",".join(fields))
|
||||
|
||||
rc = dish_common.get_data(opts,
|
||||
gstate,
|
||||
cb_data_add_item,
|
||||
cb_data_add_sequence,
|
||||
add_bulk=cb_add_bulk)
|
||||
|
||||
if opts.verbose:
|
||||
if csv_data:
|
||||
print("\n".join(csv_data))
|
||||
if opts.loop_interval > 0.0:
|
||||
print()
|
||||
else:
|
||||
# skip if only timestamp
|
||||
if len(csv_data) > 1:
|
||||
print(",".join(csv_data))
|
||||
|
||||
return rc
|
||||
|
||||
|
||||
def main():
|
||||
opts = parse_args()
|
||||
|
||||
logging.basicConfig(format="%(levelname)s: %(message)s")
|
||||
|
||||
if opts.print_header:
|
||||
print_header(opts)
|
||||
sys.exit(0)
|
||||
|
||||
gstate = dish_common.GlobalState()
|
||||
|
||||
try:
|
||||
next_loop = time.monotonic()
|
||||
while True:
|
||||
rc = loop_body(opts, gstate)
|
||||
if opts.loop_interval > 0.0:
|
||||
now = time.monotonic()
|
||||
next_loop = max(next_loop + opts.loop_interval, now)
|
||||
time.sleep(next_loop - now)
|
||||
else:
|
||||
break
|
||||
finally:
|
||||
gstate.shutdown()
|
||||
|
||||
sys.exit(rc)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
24
dump_dish_status.py
Normal file
24
dump_dish_status.py
Normal file
|
|
@ -0,0 +1,24 @@
|
|||
#!/usr/bin/python3
|
||||
"""Simple example of get_status request using grpc call directly."""
|
||||
|
||||
import grpc
|
||||
|
||||
from spacex.api.device import device_pb2
|
||||
from spacex.api.device import device_pb2_grpc
|
||||
from spacex.api.device import dish_pb2
|
||||
|
||||
# Note that if you remove the 'with' clause here, you need to separately
|
||||
# call channel.close() when you're done with the gRPC connection.
|
||||
with grpc.insecure_channel("192.168.100.1:9200") as channel:
|
||||
stub = device_pb2_grpc.DeviceStub(channel)
|
||||
response = stub.Handle(device_pb2.Request(get_status={}))
|
||||
|
||||
# Dump everything
|
||||
print(response)
|
||||
|
||||
# Just the software version
|
||||
print("Software version:", response.dish_get_status.device_info.software_version)
|
||||
|
||||
# Check if connected
|
||||
print("Connected" if response.dish_get_status.state ==
|
||||
dish_pb2.DishState.CONNECTED else "Not connected")
|
||||
88
poll_history.py
Normal file
88
poll_history.py
Normal file
|
|
@ -0,0 +1,88 @@
|
|||
#!/usr/bin/python3
|
||||
"""A simple(?) example for using the starlink_grpc module.
|
||||
|
||||
This script shows an example of how to use the starlink_grpc module to
|
||||
implement polling of status and/or history data.
|
||||
|
||||
By itself, it's not very useful unless you're trying to understand how the
|
||||
status data correlates with certain aspects of the history data because all it
|
||||
does is to dump both status and history data when it detects certain
|
||||
conditions in the history data.
|
||||
"""
|
||||
|
||||
from datetime import datetime
|
||||
from datetime import timezone
|
||||
import time
|
||||
|
||||
import starlink_grpc
|
||||
|
||||
INITIAL_SAMPLES = 20
|
||||
LOOP_SLEEP_TIME = 4
|
||||
|
||||
|
||||
def run_loop(context):
|
||||
samples = INITIAL_SAMPLES
|
||||
counter = None
|
||||
prev_triggered = False
|
||||
while True:
|
||||
try:
|
||||
# `starlink_grpc.status_data` returns a tuple of 3 dicts, but in case
|
||||
# the API changes to add more in the future, it's best to reference
|
||||
# them by index instead of direct assignment from the function call.
|
||||
groups = starlink_grpc.status_data(context=context)
|
||||
status = groups[0]
|
||||
|
||||
# On the other hand, `starlink_grpc.history_bulk_data` will always
|
||||
# return 2 dicts, because that's all the data there is.
|
||||
general, bulk = starlink_grpc.history_bulk_data(samples, start=counter, context=context)
|
||||
except starlink_grpc.GrpcError:
|
||||
# Dish rebooting maybe, or LAN connectivity error. Just ignore it
|
||||
# and hope it goes away.
|
||||
pass
|
||||
else:
|
||||
# The following is what actually does stuff with the data. It should
|
||||
# be replaced with something more useful.
|
||||
|
||||
# This computes a trigger detecting any packet loss (ping drop):
|
||||
#triggered = any(x > 0 for x in bulk["pop_ping_drop_rate"])
|
||||
# This computes a trigger detecting samples marked as obstructed:
|
||||
#triggered = any(bulk["obstructed"])
|
||||
# This computes a trigger detecting samples not marked as scheduled:
|
||||
triggered = not all(bulk["scheduled"])
|
||||
if triggered or prev_triggered:
|
||||
print("Triggered" if triggered else "Continued", "at:",
|
||||
datetime.now(tz=timezone.utc))
|
||||
print("status:", status)
|
||||
print("history:", bulk)
|
||||
if not triggered:
|
||||
print()
|
||||
|
||||
prev_triggered = triggered
|
||||
# The following makes the next loop only pull the history samples that
|
||||
# are newer than the ones already examined.
|
||||
samples = -1
|
||||
counter = general["end_counter"]
|
||||
|
||||
# And this is a not-very-robust way of implementing an interval loop.
|
||||
# Note that a 4 second loop will poll the history buffer pretty
|
||||
# frequently. Even though we only ask for new samples (which should
|
||||
# only be 4 of them), the grpc layer needs to pull the entire 12 hour
|
||||
# history buffer each time, only to discard most of it.
|
||||
time.sleep(LOOP_SLEEP_TIME)
|
||||
|
||||
|
||||
def main():
|
||||
# This part is optional. The `starlink_grpc` functions can work without a
|
||||
# `starlink_grpc.ChannelContext` object passed in, but they will open a
|
||||
# new channel for each RPC call (so twice for each loop iteration) without
|
||||
# it.
|
||||
context = starlink_grpc.ChannelContext()
|
||||
|
||||
try:
|
||||
run_loop(context)
|
||||
finally:
|
||||
context.close()
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
829
starlink_grpc.py
829
starlink_grpc.py
|
|
@ -1,126 +1,308 @@
|
|||
"""Helpers for grpc communication with a Starlink user terminal.
|
||||
|
||||
This module may eventually contain more expansive parsing logic, but for now
|
||||
it contains functions to either get the history data as-is or parse it for
|
||||
some specific packet loss statistics.
|
||||
This module contains functions for getting the history and status data and
|
||||
either return it as-is or parsed for some specific statistics.
|
||||
|
||||
Those functions return data grouped into sets, as follows:
|
||||
Those functions return data grouped into sets, as follows.
|
||||
|
||||
General data:
|
||||
This set of fields contains data relevant to all the other groups.
|
||||
Note:
|
||||
Functions that return field names may indicate which fields hold sequences
|
||||
(which are not necessarily lists) instead of single items. The field names
|
||||
returned in those cases will be in one of the following formats:
|
||||
|
||||
The sample interval is currently 1 second.
|
||||
: "name[]" : A sequence of indeterminate size (or a size that can be
|
||||
determined from other parts of the returned data).
|
||||
: "name[n]" : A sequence with exactly n elements.
|
||||
: "name[n1,]" : A sequence of indeterminate size with recommended starting
|
||||
index label n1.
|
||||
: "name[n1,n2]" : A sequence with n2-n1 elements with recommended starting
|
||||
index label n1. This is similar to the args to range() builtin.
|
||||
|
||||
samples: The number of samples analyzed (for statistics) or returned
|
||||
For example, the field name "foo[1,5]" could be expanded to "foo_1",
|
||||
"foo_2", "foo_3", and "foo_4" (or however else the caller wants to
|
||||
indicate index numbers, if at all).
|
||||
|
||||
General status data
|
||||
-------------------
|
||||
This group holds information about the current state of the user terminal.
|
||||
|
||||
: **id** : A string identifying the specific user terminal device that was
|
||||
reachable from the local network. Something like a serial number.
|
||||
: **hardware_version** : A string identifying the user terminal hardware
|
||||
version.
|
||||
: **software_version** : A string identifying the software currently installed
|
||||
on the user terminal.
|
||||
: **state** : As string describing the current connectivity state of the user
|
||||
terminal. One of: "UNKNOWN", "CONNECTED", "SEARCHING", "BOOTING".
|
||||
: **uptime** : The amount of time, in seconds, since the user terminal last
|
||||
rebooted.
|
||||
: **snr** : Most recent sample value. See bulk history data for detail.
|
||||
: **seconds_to_first_nonempty_slot** : Amount of time from now, in seconds,
|
||||
until a satellite will be scheduled to be available for transmit/receive.
|
||||
See also *scheduled* in the bulk history data. May report as a negative
|
||||
number, which appears to indicate unknown time until next satellite
|
||||
scheduled and usually correlates with *state* reporting as other than
|
||||
"CONNECTED".
|
||||
: **pop_ping_drop_rate** : Most recent sample value. See bulk history data for
|
||||
detail.
|
||||
: **downlink_throughput_bps** : Most recent sample value. See bulk history
|
||||
data for detail.
|
||||
: **uplink_throughput_bps** : Most recent sample value. See bulk history data
|
||||
for detail.
|
||||
: **pop_ping_latency_ms** : Most recent sample value. See bulk history data
|
||||
for detail.
|
||||
: **alerts** : A bit field combining all active alerts, where a 1 bit
|
||||
indicates the alert is active. See alert detail status data for which bits
|
||||
correspond with each alert, or to get individual alert flags instead of a
|
||||
combined bit mask.
|
||||
: **fraction_obstructed** : The fraction of total area (or possibly fraction
|
||||
of time?) that the user terminal has determined to be obstructed between
|
||||
it and the satellites with which it communicates.
|
||||
: **currently_obstructed** : Most recent sample value. See bulk history data
|
||||
for detail.
|
||||
: **seconds_obstructed** : The amount of time within the history buffer
|
||||
(currently the smaller of 12 hours or since last reboot), in seconds that
|
||||
the user terminal determined to be obstructed, regardless of whether or
|
||||
not packets were able to be transmitted or received. See also
|
||||
*count_obstructed* in general ping drop history data; this value will be
|
||||
equal to that value when computed across all available history samples.
|
||||
|
||||
Obstruction detail status data
|
||||
------------------------------
|
||||
This group holds additional detail regarding the specific areas the user
|
||||
terminal has determined to be obstructed.
|
||||
|
||||
: **wedges_fraction_obstructed** : A 12 element sequence. Each element
|
||||
represents a 30 degree wedge of area and its value indicates the fraction
|
||||
of area (time?) within that wedge that the user terminal has determined to
|
||||
be obstructed between it and the satellites with which it communicates.
|
||||
The values are expressed as a fraction of total, not a fraction of the
|
||||
wedge, so max value for each element should be 1/12. The first element in
|
||||
the sequence represents the wedge that spans exactly North to 30 degrees
|
||||
East of North, and subsequent wedges rotate 30 degrees further in the same
|
||||
direction. (It's not clear if this will hold true at all latitudes.)
|
||||
: **valid_s** : It is unclear what this field means exactly, but it appears to
|
||||
be a measure of how complete the data is that the user terminal uses to
|
||||
determine obstruction locations.
|
||||
|
||||
See also *fraction_obstructed* in general status data, which should equal the
|
||||
sum of all *wedges_fraction_obstructed* elements.
|
||||
|
||||
Alert detail status data
|
||||
------------------------
|
||||
This group holds the current state of each individual alert reported by the
|
||||
user terminal. Note that more alerts may be added in the future. See also
|
||||
*alerts* in the general status data for a bit field combining them if you
|
||||
need a set of fields that will not change size in the future.
|
||||
|
||||
Descriptions on these are vague due to them being difficult to confirm by
|
||||
their nature, but the field names are pretty self-explanatory.
|
||||
|
||||
: **alert_motors_stuck** : Alert corresponding with bit 0 (bit mask 1) in
|
||||
*alerts*.
|
||||
: **alert_thermal_throttle** : Alert corresponding with bit 1 (bit mask 2) in
|
||||
*alerts*.
|
||||
: **alert_thermal_shutdown** : Alert corresponding with bit 2 (bit mask 4) in
|
||||
*alerts*.
|
||||
: **alert_unexpected_location** : Alert corresponding with bit 3 (bit mask 8)
|
||||
in *alerts*.
|
||||
|
||||
General history data
|
||||
--------------------
|
||||
This set of fields contains data relevant to all the other history groups.
|
||||
|
||||
The sample interval is currently 1 second.
|
||||
|
||||
: **samples** : The number of samples analyzed (for statistics) or returned
|
||||
(for bulk data).
|
||||
end_counter: The total number of data samples that have been written to
|
||||
the history buffer since dish reboot, irrespective of buffer wrap.
|
||||
This can be used to keep track of how many samples are new in
|
||||
comparison to a prior query of the history data.
|
||||
: **end_counter** : The total number of data samples that have been written to
|
||||
the history buffer since reboot of the user terminal, irrespective of
|
||||
buffer wrap. This can be used to keep track of how many samples are new
|
||||
in comparison to a prior query of the history data.
|
||||
|
||||
Bulk history data:
|
||||
This group holds the history data as-is for the requested range of
|
||||
samples, just unwound from the circular buffers that the raw data holds.
|
||||
It contains some of the same fields as the status info, but instead of
|
||||
representing the current values, each field contains a sequence of values
|
||||
representing the value over time, ending at the current time.
|
||||
Bulk history data
|
||||
-----------------
|
||||
This group holds the history data as-is for the requested range of
|
||||
samples, just unwound from the circular buffers that the raw data holds.
|
||||
It contains some of the same fields as the status info, but instead of
|
||||
representing the current values, each field contains a sequence of values
|
||||
representing the value over time, ending at the current time.
|
||||
|
||||
pop_ping_drop_rate: Fraction of lost ping replies per sample.
|
||||
pop_ping_latency_ms: Round trip time, in milliseconds, during the
|
||||
: **pop_ping_drop_rate** : Fraction of lost ping replies per sample.
|
||||
: **pop_ping_latency_ms** : Round trip time, in milliseconds, during the
|
||||
sample period, or None if a sample experienced 100% ping drop.
|
||||
downlink_throughput_bps: Download usage during the sample period
|
||||
: **downlink_throughput_bps** : Download usage during the sample period
|
||||
(actual, not max available), in bits per second.
|
||||
uplink_throughput_bps: Upload usage during the sample period, in bits
|
||||
: **uplink_throughput_bps** : Upload usage during the sample period, in bits
|
||||
per second.
|
||||
snr: Signal to noise ratio during the sample period.
|
||||
scheduled: Boolean indicating whether or not a satellite was scheduled
|
||||
to be available for transmit/receive during the sample period.
|
||||
When false, ping drop shows as "No satellites" in Starlink app.
|
||||
obstructed: Boolean indicating whether or not the dish determined the
|
||||
signal between it and the satellite was obstructed during the
|
||||
sample period. When true, ping drop shows as "Obstructed" in the
|
||||
: **snr** : Signal to noise ratio during the sample period.
|
||||
: **scheduled** : Boolean indicating whether or not a satellite was scheduled
|
||||
to be available for transmit/receive during the sample period. When
|
||||
false, ping drop shows as "No satellites" in Starlink app.
|
||||
: **obstructed** : Boolean indicating whether or not the user terminal
|
||||
determined the signal between it and the satellite was obstructed during
|
||||
the sample period. When true, ping drop shows as "Obstructed" in the
|
||||
Starlink app.
|
||||
|
||||
There is no specific data field in the raw history data that directly
|
||||
correlates with "Other" or "Beta downtime" in the Starlink app (or
|
||||
whatever it gets renamed to after beta), but empirical evidence suggests
|
||||
any sample where pop_ping_drop_rate is 1, scheduled is true, and
|
||||
obstructed is false is counted as "Beta downtime".
|
||||
There is no specific data field in the raw history data that directly
|
||||
correlates with "Other" or "Beta downtime" in the Starlink app (or whatever it
|
||||
gets renamed to after beta), but empirical evidence suggests any sample where
|
||||
*pop_ping_drop_rate* is 1, *scheduled* is true, and *obstructed* is false is
|
||||
counted as "Beta downtime".
|
||||
|
||||
Note that neither scheduled=false nor obstructed=true necessarily means
|
||||
packet loss occurred. Those need to be examined in combination with
|
||||
pop_ping_drop_rate to be meaningful.
|
||||
Note that neither *scheduled*=false nor *obstructed*=true necessarily means
|
||||
packet loss occurred. Those need to be examined in combination with
|
||||
*pop_ping_drop_rate* to be meaningful.
|
||||
|
||||
General ping drop (packet loss) statistics:
|
||||
This group of statistics characterize the packet loss (labeled "ping drop"
|
||||
in the field names of the Starlink gRPC service protocol) in various ways.
|
||||
General ping drop history statistics
|
||||
------------------------------------
|
||||
This group of statistics characterize the packet loss (labeled "ping drop" in
|
||||
the field names of the Starlink gRPC service protocol) in various ways.
|
||||
|
||||
total_ping_drop: The total amount of time, in sample intervals, that
|
||||
: **total_ping_drop** : The total amount of time, in sample intervals, that
|
||||
experienced ping drop.
|
||||
count_full_ping_drop: The number of samples that experienced 100%
|
||||
ping drop.
|
||||
count_obstructed: The number of samples that were marked as
|
||||
: **count_full_ping_drop** : The number of samples that experienced 100% ping
|
||||
drop.
|
||||
: **count_obstructed** : The number of samples that were marked as
|
||||
"obstructed", regardless of whether they experienced any ping
|
||||
drop.
|
||||
total_obstructed_ping_drop: The total amount of time, in sample
|
||||
intervals, that experienced ping drop in samples marked as
|
||||
"obstructed".
|
||||
count_full_obstructed_ping_drop: The number of samples that were
|
||||
marked as "obstructed" and that experienced 100% ping drop.
|
||||
count_unscheduled: The number of samples that were not marked as
|
||||
"scheduled", regardless of whether they experienced any ping
|
||||
drop.
|
||||
total_unscheduled_ping_drop: The total amount of time, in sample
|
||||
: **total_obstructed_ping_drop** : The total amount of time, in sample
|
||||
intervals, that experienced ping drop in samples marked as "obstructed".
|
||||
: **count_full_obstructed_ping_drop** : The number of samples that were marked
|
||||
as "obstructed" and that experienced 100% ping drop.
|
||||
: **count_unscheduled** : The number of samples that were not marked as
|
||||
"scheduled", regardless of whether they experienced any ping drop.
|
||||
: **total_unscheduled_ping_drop** : The total amount of time, in sample
|
||||
intervals, that experienced ping drop in samples not marked as
|
||||
"scheduled".
|
||||
count_full_unscheduled_ping_drop: The number of samples that were
|
||||
not marked as "scheduled" and that experienced 100% ping drop.
|
||||
: **count_full_unscheduled_ping_drop** : The number of samples that were not
|
||||
marked as "scheduled" and that experienced 100% ping drop.
|
||||
|
||||
Total packet loss ratio can be computed with total_ping_drop / samples.
|
||||
Total packet loss ratio can be computed with *total_ping_drop* / *samples*.
|
||||
|
||||
Ping drop run length statistics:
|
||||
This group of statistics characterizes packet loss by how long a
|
||||
consecutive run of 100% packet loss lasts.
|
||||
Ping drop run length history statistics
|
||||
---------------------------------------
|
||||
This group of statistics characterizes packet loss by how long a
|
||||
consecutive run of 100% packet loss lasts.
|
||||
|
||||
init_run_fragment: The number of consecutive sample periods at the
|
||||
start of the sample set that experienced 100% ping drop. This
|
||||
period may be a continuation of a run that started prior to the
|
||||
sample set, so is not counted in the following stats.
|
||||
final_run_fragment: The number of consecutive sample periods at the
|
||||
end of the sample set that experienced 100% ping drop. This
|
||||
period may continue as a run beyond the end of the sample set, so
|
||||
is not counted in the following stats.
|
||||
run_seconds: A 60 element sequence. Each element records the total
|
||||
amount of time, in sample intervals, that experienced 100% ping
|
||||
drop in a consecutive run that lasted for (index + 1) sample
|
||||
intervals (seconds). That is, the first element contains time
|
||||
spent in 1 sample runs, the second element contains time spent in
|
||||
2 sample runs, etc.
|
||||
run_minutes: A 60 element sequence. Each element records the total
|
||||
amount of time, in sample intervals, that experienced 100% ping
|
||||
drop in a consecutive run that lasted for more that (index + 1)
|
||||
multiples of 60 sample intervals (minutes), but less than or equal
|
||||
to (index + 2) multiples of 60 sample intervals. Except for the
|
||||
last element in the sequence, which records the total amount of
|
||||
time in runs of more than 60*60 samples.
|
||||
: **init_run_fragment** : The number of consecutive sample periods at the
|
||||
start of the sample set that experienced 100% ping drop. This period may
|
||||
be a continuation of a run that started prior to the sample set, so is not
|
||||
counted in the following stats.
|
||||
: **final_run_fragment** : The number of consecutive sample periods at the end
|
||||
of the sample set that experienced 100% ping drop. This period may
|
||||
continue as a run beyond the end of the sample set, so is not counted in
|
||||
the following stats.
|
||||
: **run_seconds** : A 60 element sequence. Each element records the total
|
||||
amount of time, in sample intervals, that experienced 100% ping drop in a
|
||||
consecutive run that lasted for (index + 1) sample intervals (seconds).
|
||||
That is, the first element contains time spent in 1 sample runs, the
|
||||
second element contains time spent in 2 sample runs, etc.
|
||||
: **run_minutes** : A 60 element sequence. Each element records the total
|
||||
amount of time, in sample intervals, that experienced 100% ping drop in a
|
||||
consecutive run that lasted for more that (index + 1) multiples of 60
|
||||
sample intervals (minutes), but less than or equal to (index + 2)
|
||||
multiples of 60 sample intervals. Except for the last element in the
|
||||
sequence, which records the total amount of time in runs of more than
|
||||
60*60 samples.
|
||||
|
||||
No sample should be counted in more than one of the run length stats or
|
||||
stat elements, so the total of all of them should be equal to
|
||||
count_full_ping_drop from the ping drop stats.
|
||||
No sample should be counted in more than one of the run length stats or stat
|
||||
elements, so the total of all of them should be equal to
|
||||
*count_full_ping_drop* from the ping drop stats.
|
||||
|
||||
Samples that experience less than 100% ping drop are not counted in this
|
||||
group of stats, even if they happen at the beginning or end of a run of
|
||||
100% ping drop samples. To compute the amount of time that experienced
|
||||
ping loss in less than a single run of 100% ping drop, use
|
||||
(total_ping_drop - count_full_ping_drop) from the ping drop stats.
|
||||
Samples that experience less than 100% ping drop are not counted in this group
|
||||
of stats, even if they happen at the beginning or end of a run of 100% ping
|
||||
drop samples. To compute the amount of time that experienced ping loss in less
|
||||
than a single run of 100% ping drop, use (*total_ping_drop* -
|
||||
*count_full_ping_drop*) from the ping drop stats.
|
||||
|
||||
Ping latency history statistics
|
||||
-------------------------------
|
||||
This group of statistics characterizes latency of ping request/response in
|
||||
various ways. For all non-sequence fields and most sequence elements, the
|
||||
value may report as None to indicate no matching samples. The exception is
|
||||
*load_bucket_samples* elements, which report 0 for no matching samples.
|
||||
|
||||
The fields that have "all" in their name are computed across all samples that
|
||||
had any ping success (ping drop < 1). The fields that have "full" in their
|
||||
name are computed across only the samples that have 100% ping success (ping
|
||||
drop = 0). Which one is more interesting may depend on intended use. High rate
|
||||
of packet loss appears to cause outlier latency values on the high side. On
|
||||
the one hand, those are real cases, so should not be dismissed lightly. On the
|
||||
other hand, the "full" numbers are more directly comparable to sample sets
|
||||
taken over time.
|
||||
|
||||
: **mean_all_ping_latency** : Weighted mean latency value, in milliseconds, of
|
||||
all samples that experienced less than 100% ping drop. Values are weighted
|
||||
by amount of ping success (1 - ping drop).
|
||||
: **deciles_all_ping_latency** : An 11 element sequence recording the weighted
|
||||
deciles (10-quantiles) of latency values, in milliseconds, for all samples
|
||||
that experienced less that 100% ping drop, including the minimum and
|
||||
maximum values as the 0th and 10th deciles respectively. The 5th decile
|
||||
(at sequence index 5) is the weighted median latency value.
|
||||
: **mean_full_ping_latency** : Mean latency value, in milliseconds, of samples
|
||||
that experienced no ping drop.
|
||||
: **deciles_full_ping_latency** : An 11 element sequence recording the deciles
|
||||
(10-quantiles) of latency values, in milliseconds, for all samples that
|
||||
experienced no ping drop, including the minimum and maximum values as the
|
||||
0th and 10th deciles respectively. The 5th decile (at sequence index 5) is
|
||||
the median latency value.
|
||||
: **stdev_full_ping_latency** : Population standard deviation of the latency
|
||||
value of samples that experienced no ping drop.
|
||||
|
||||
Loaded ping latency statistics
|
||||
------------------------------
|
||||
This group of statistics attempts to characterize latency of ping
|
||||
request/response under various network load conditions. Samples are grouped by
|
||||
total (down+up) bandwidth used during the sample period, using a log base 2
|
||||
scale. These groups are referred to as "load buckets" below. The first bucket
|
||||
in each sequence represents samples that use less than 1Mbps (millions of bits
|
||||
per second). Subsequent buckets use more bandwidth than that covered by prior
|
||||
buckets, but less than twice the maximum bandwidth of the immediately prior
|
||||
bucket. The last bucket, at sequence index 14, represents all samples not
|
||||
covered by a prior bucket, which works out to any sample using 8192Mbps or
|
||||
greater. Only samples that experience no ping drop are included in any of the
|
||||
buckets.
|
||||
|
||||
This group of fields should be considered EXPERIMENTAL and thus subject to
|
||||
change without regard to backward compatibility.
|
||||
|
||||
Note that in all cases, the latency values are of "ping" traffic, which may be
|
||||
prioritized lower than other traffic by various network layers. How much
|
||||
bandwidth constitutes a fully loaded network connection may vary over time.
|
||||
Buckets with few samples may not contain statistically significant latency
|
||||
data.
|
||||
|
||||
: **load_bucket_samples** : A 15 element sequence recording the number of
|
||||
samples per load bucket. See above for load bucket partitioning.
|
||||
EXPERIMENTAL.
|
||||
: **load_bucket_min_latency** : A 15 element sequence recording the minimum
|
||||
latency value, in milliseconds, per load bucket. EXPERIMENTAL.
|
||||
: **load_bucket_median_latency** : A 15 element sequence recording the median
|
||||
latency value, in milliseconds, per load bucket. EXPERIMENTAL.
|
||||
: **load_bucket_max_latency** : A 15 element sequence recording the maximum
|
||||
latency value, in milliseconds, per load bucket. EXPERIMENTAL.
|
||||
|
||||
Bandwidth usage history statistics
|
||||
----------------------------------
|
||||
This group of statistics characterizes total bandwidth usage over the sample
|
||||
period.
|
||||
|
||||
: **download_usage** : Total number of bytes downloaded to the user terminal
|
||||
during the sample period.
|
||||
: **upload_usage** : Total number of bytes uploaded from the user terminal
|
||||
during the sample period.
|
||||
"""
|
||||
|
||||
from itertools import chain
|
||||
import math
|
||||
import statistics
|
||||
|
||||
import grpc
|
||||
|
||||
import spacex.api.device.device_pb2
|
||||
import spacex.api.device.device_pb2_grpc
|
||||
from spacex.api.device import device_pb2
|
||||
from spacex.api.device import device_pb2_grpc
|
||||
from spacex.api.device import dish_pb2
|
||||
|
||||
|
||||
class GrpcError(Exception):
|
||||
|
|
@ -137,21 +319,134 @@ class GrpcError(Exception):
|
|||
super().__init__(msg, *args, **kwargs)
|
||||
|
||||
|
||||
def get_status():
|
||||
class ChannelContext:
|
||||
"""A wrapper for reusing an open grpc Channel across calls.
|
||||
|
||||
`close()` should be called on the object when it is no longer
|
||||
in use.
|
||||
"""
|
||||
def __init__(self, target="192.168.100.1:9200"):
|
||||
self.channel = None
|
||||
self.target = target
|
||||
|
||||
def get_channel(self):
|
||||
reused = True
|
||||
if self.channel is None:
|
||||
self.channel = grpc.insecure_channel(self.target)
|
||||
reused = False
|
||||
return self.channel, reused
|
||||
|
||||
def close(self):
|
||||
if self.channel is not None:
|
||||
self.channel.close()
|
||||
self.channel = None
|
||||
|
||||
|
||||
def status_field_names():
|
||||
"""Return the field names of the status data.
|
||||
|
||||
Note:
|
||||
See module level docs regarding brackets in field names.
|
||||
|
||||
Returns:
|
||||
A tuple with 3 lists, with status data field names, alert detail field
|
||||
names, and obstruction detail field names, in that order.
|
||||
"""
|
||||
alert_names = []
|
||||
for field in dish_pb2.DishAlerts.DESCRIPTOR.fields:
|
||||
alert_names.append("alert_" + field.name)
|
||||
|
||||
return [
|
||||
"id",
|
||||
"hardware_version",
|
||||
"software_version",
|
||||
"state",
|
||||
"uptime",
|
||||
"snr",
|
||||
"seconds_to_first_nonempty_slot",
|
||||
"pop_ping_drop_rate",
|
||||
"downlink_throughput_bps",
|
||||
"uplink_throughput_bps",
|
||||
"pop_ping_latency_ms",
|
||||
"alerts",
|
||||
"fraction_obstructed",
|
||||
"currently_obstructed",
|
||||
"seconds_obstructed",
|
||||
], [
|
||||
"wedges_fraction_obstructed[12]",
|
||||
"valid_s",
|
||||
], alert_names
|
||||
|
||||
|
||||
def status_field_types():
|
||||
"""Return the field types of the status data.
|
||||
|
||||
Return the type classes for each field. For sequence types, the type of
|
||||
element in the sequence is returned, not the type of the sequence.
|
||||
|
||||
Returns:
|
||||
A tuple with 3 lists, with status data field types, alert detail field
|
||||
types, and obstruction detail field types, in that order.
|
||||
"""
|
||||
return [
|
||||
str, # id
|
||||
str, # hardware_version
|
||||
str, # software_version
|
||||
str, # state
|
||||
int, # uptime
|
||||
float, # snr
|
||||
float, # seconds_to_first_nonempty_slot
|
||||
float, # pop_ping_drop_rate
|
||||
float, # downlink_throughput_bps
|
||||
float, # uplink_throughput_bps
|
||||
float, # pop_ping_latency_ms
|
||||
int, # alerts
|
||||
float, # fraction_obstructed
|
||||
bool, # currently_obstructed
|
||||
float, # seconds_obstructed
|
||||
], [
|
||||
float, # wedges_fraction_obstructed[]
|
||||
float, # valid_s
|
||||
], [bool] * len(dish_pb2.DishAlerts.DESCRIPTOR.fields)
|
||||
|
||||
|
||||
def get_status(context=None):
|
||||
"""Fetch status data and return it in grpc structure format.
|
||||
|
||||
Args:
|
||||
context (ChannelContext): Optionally provide a channel for reuse
|
||||
across repeated calls. If an existing channel is reused, the RPC
|
||||
call will be retried at most once, since connectivity may have
|
||||
been lost and restored in the time since it was last used.
|
||||
|
||||
Raises:
|
||||
grpc.RpcError: Communication or service error.
|
||||
"""
|
||||
if context is None:
|
||||
with grpc.insecure_channel("192.168.100.1:9200") as channel:
|
||||
stub = spacex.api.device.device_pb2_grpc.DeviceStub(channel)
|
||||
response = stub.Handle(spacex.api.device.device_pb2.Request(get_status={}))
|
||||
stub = device_pb2_grpc.DeviceStub(channel)
|
||||
response = stub.Handle(device_pb2.Request(get_status={}))
|
||||
return response.dish_get_status
|
||||
|
||||
while True:
|
||||
channel, reused = context.get_channel()
|
||||
try:
|
||||
stub = device_pb2_grpc.DeviceStub(channel)
|
||||
response = stub.Handle(device_pb2.Request(get_status={}))
|
||||
return response.dish_get_status
|
||||
except grpc.RpcError:
|
||||
context.close()
|
||||
if not reused:
|
||||
raise
|
||||
|
||||
def get_id():
|
||||
|
||||
def get_id(context=None):
|
||||
"""Return the ID from the dish status information.
|
||||
|
||||
Args:
|
||||
context (ChannelContext): Optionally provide a channel for reuse
|
||||
across repeated calls.
|
||||
|
||||
Returns:
|
||||
A string identifying the Starlink user terminal reachable from the
|
||||
local network.
|
||||
|
|
@ -160,19 +455,133 @@ def get_id():
|
|||
GrpcError: No user terminal is currently reachable.
|
||||
"""
|
||||
try:
|
||||
status = get_status()
|
||||
status = get_status(context)
|
||||
return status.device_info.id
|
||||
except grpc.RpcError as e:
|
||||
raise GrpcError(e)
|
||||
|
||||
|
||||
def history_ping_field_names():
|
||||
"""Return the field names of the packet loss stats.
|
||||
def status_data(context=None):
|
||||
"""Fetch current status data.
|
||||
|
||||
Args:
|
||||
context (ChannelContext): Optionally provide a channel for reuse
|
||||
across repeated calls.
|
||||
|
||||
Returns:
|
||||
A tuple with 3 lists, the first with general data names, the second
|
||||
with ping drop stat names, and the third with ping drop run length
|
||||
stat names.
|
||||
A tuple with 3 dicts, mapping status data field names, alert detail
|
||||
field names, and obstruction detail field names to their respective
|
||||
values, in that order.
|
||||
|
||||
Raises:
|
||||
GrpcError: Failed getting history info from the Starlink user
|
||||
terminal.
|
||||
"""
|
||||
try:
|
||||
status = get_status(context)
|
||||
except grpc.RpcError as e:
|
||||
raise GrpcError(e)
|
||||
|
||||
# More alerts may be added in future, so in addition to listing them
|
||||
# individually, provide a bit field based on field numbers of the
|
||||
# DishAlerts message.
|
||||
alerts = {}
|
||||
alert_bits = 0
|
||||
for field in status.alerts.DESCRIPTOR.fields:
|
||||
value = getattr(status.alerts, field.name)
|
||||
alerts["alert_" + field.name] = value
|
||||
alert_bits |= (1 if value else 0) << (field.index)
|
||||
|
||||
return {
|
||||
"id": status.device_info.id,
|
||||
"hardware_version": status.device_info.hardware_version,
|
||||
"software_version": status.device_info.software_version,
|
||||
"state": dish_pb2.DishState.Name(status.state),
|
||||
"uptime": status.device_state.uptime_s,
|
||||
"snr": status.snr,
|
||||
"seconds_to_first_nonempty_slot": status.seconds_to_first_nonempty_slot,
|
||||
"pop_ping_drop_rate": status.pop_ping_drop_rate,
|
||||
"downlink_throughput_bps": status.downlink_throughput_bps,
|
||||
"uplink_throughput_bps": status.uplink_throughput_bps,
|
||||
"pop_ping_latency_ms": status.pop_ping_latency_ms,
|
||||
"alerts": alert_bits,
|
||||
"fraction_obstructed": status.obstruction_stats.fraction_obstructed,
|
||||
"currently_obstructed": status.obstruction_stats.currently_obstructed,
|
||||
"seconds_obstructed": status.obstruction_stats.last_24h_obstructed_s,
|
||||
}, {
|
||||
"wedges_fraction_obstructed[]": status.obstruction_stats.wedge_abs_fraction_obstructed,
|
||||
"valid_s": status.obstruction_stats.valid_s,
|
||||
}, alerts
|
||||
|
||||
|
||||
def history_bulk_field_names():
|
||||
"""Return the field names of the bulk history data.
|
||||
|
||||
Note:
|
||||
See module level docs regarding brackets in field names.
|
||||
|
||||
Returns:
|
||||
A tuple with 2 lists, the first with general data names, the second
|
||||
with bulk history data names.
|
||||
"""
|
||||
return [
|
||||
"samples",
|
||||
"end_counter",
|
||||
], [
|
||||
"pop_ping_drop_rate[]",
|
||||
"pop_ping_latency_ms[]",
|
||||
"downlink_throughput_bps[]",
|
||||
"uplink_throughput_bps[]",
|
||||
"snr[]",
|
||||
"scheduled[]",
|
||||
"obstructed[]",
|
||||
]
|
||||
|
||||
|
||||
def history_bulk_field_types():
|
||||
"""Return the field types of the bulk history data.
|
||||
|
||||
Return the type classes for each field. For sequence types, the type of
|
||||
element in the sequence is returned, not the type of the sequence.
|
||||
|
||||
Returns:
|
||||
A tuple with 2 lists, the first with general data types, the second
|
||||
with bulk history data types.
|
||||
"""
|
||||
return [
|
||||
int, # samples
|
||||
int, # end_counter
|
||||
], [
|
||||
float, # pop_ping_drop_rate[]
|
||||
float, # pop_ping_latency_ms[]
|
||||
float, # downlink_throughput_bps[]
|
||||
float, # uplink_throughput_bps[]
|
||||
float, # snr[]
|
||||
bool, # scheduled[]
|
||||
bool, # obstructed[]
|
||||
]
|
||||
|
||||
|
||||
def history_ping_field_names():
|
||||
"""Deprecated. Use history_stats_field_names instead."""
|
||||
return history_stats_field_names()[0:3]
|
||||
|
||||
|
||||
def history_stats_field_names():
|
||||
"""Return the field names of the packet loss stats.
|
||||
|
||||
Note:
|
||||
See module level docs regarding brackets in field names.
|
||||
|
||||
Returns:
|
||||
A tuple with 6 lists, with general data names, ping drop stat names,
|
||||
ping drop run length stat names, ping latency stat names, loaded ping
|
||||
latency stat names, and bandwidth usage stat names, in that order.
|
||||
|
||||
Note:
|
||||
Additional lists may be added to this tuple in the future with
|
||||
additional data groups, so it not recommended for the caller to
|
||||
assume exactly 6 elements.
|
||||
"""
|
||||
return [
|
||||
"samples",
|
||||
|
|
@ -189,22 +598,104 @@ def history_ping_field_names():
|
|||
], [
|
||||
"init_run_fragment",
|
||||
"final_run_fragment",
|
||||
"run_seconds",
|
||||
"run_minutes",
|
||||
"run_seconds[1,61]",
|
||||
"run_minutes[1,61]",
|
||||
], [
|
||||
"mean_all_ping_latency",
|
||||
"deciles_all_ping_latency[11]",
|
||||
"mean_full_ping_latency",
|
||||
"deciles_full_ping_latency[11]",
|
||||
"stdev_full_ping_latency",
|
||||
], [
|
||||
"load_bucket_samples[15]",
|
||||
"load_bucket_min_latency[15]",
|
||||
"load_bucket_median_latency[15]",
|
||||
"load_bucket_max_latency[15]",
|
||||
], [
|
||||
"download_usage",
|
||||
"upload_usage",
|
||||
]
|
||||
|
||||
|
||||
def get_history():
|
||||
def history_stats_field_types():
|
||||
"""Return the field types of the packet loss stats.
|
||||
|
||||
Return the type classes for each field. For sequence types, the type of
|
||||
element in the sequence is returned, not the type of the sequence.
|
||||
|
||||
Returns:
|
||||
A tuple with 6 lists, with general data types, ping drop stat types,
|
||||
ping drop run length stat types, ping latency stat types, loaded ping
|
||||
latency stat types, and bandwidth usage stat types, in that order.
|
||||
|
||||
Note:
|
||||
Additional lists may be added to this tuple in the future with
|
||||
additional data groups, so it not recommended for the caller to
|
||||
assume exactly 6 elements.
|
||||
"""
|
||||
return [
|
||||
int, # samples
|
||||
int, # end_counter
|
||||
], [
|
||||
float, # total_ping_drop
|
||||
int, # count_full_ping_drop
|
||||
int, # count_obstructed
|
||||
float, # total_obstructed_ping_drop
|
||||
int, # count_full_obstructed_ping_drop
|
||||
int, # count_unscheduled
|
||||
float, # total_unscheduled_ping_drop
|
||||
int, # count_full_unscheduled_ping_drop
|
||||
], [
|
||||
int, # init_run_fragment
|
||||
int, # final_run_fragment
|
||||
int, # run_seconds[]
|
||||
int, # run_minutes[]
|
||||
], [
|
||||
float, # mean_all_ping_latency
|
||||
float, # deciles_all_ping_latency[]
|
||||
float, # mean_full_ping_latency
|
||||
float, # deciles_full_ping_latency[]
|
||||
float, # stdev_full_ping_latency
|
||||
], [
|
||||
int, # load_bucket_samples[]
|
||||
float, # load_bucket_min_latency[]
|
||||
float, # load_bucket_median_latency[]
|
||||
float, # load_bucket_max_latency[]
|
||||
], [
|
||||
int, # download_usage
|
||||
int, # upload_usage
|
||||
]
|
||||
|
||||
|
||||
def get_history(context=None):
|
||||
"""Fetch history data and return it in grpc structure format.
|
||||
|
||||
Args:
|
||||
context (ChannelContext): Optionally provide a channel for reuse
|
||||
across repeated calls. If an existing channel is reused, the RPC
|
||||
call will be retried at most once, since connectivity may have
|
||||
been lost and restored in the time since it was last used.
|
||||
|
||||
Raises:
|
||||
grpc.RpcError: Communication or service error.
|
||||
"""
|
||||
if context is None:
|
||||
with grpc.insecure_channel("192.168.100.1:9200") as channel:
|
||||
stub = spacex.api.device.device_pb2_grpc.DeviceStub(channel)
|
||||
response = stub.Handle(spacex.api.device.device_pb2.Request(get_history={}))
|
||||
stub = device_pb2_grpc.DeviceStub(channel)
|
||||
response = stub.Handle(device_pb2.Request(get_history={}))
|
||||
return response.dish_get_history
|
||||
|
||||
while True:
|
||||
channel, reused = context.get_channel()
|
||||
try:
|
||||
stub = device_pb2_grpc.DeviceStub(channel)
|
||||
response = stub.Handle(device_pb2.Request(get_history={}))
|
||||
return response.dish_get_history
|
||||
except grpc.RpcError:
|
||||
context.close()
|
||||
if not reused:
|
||||
raise
|
||||
|
||||
|
||||
def _compute_sample_range(history, parse_samples, start=None, verbose=False):
|
||||
current = int(history.current)
|
||||
|
|
@ -245,7 +736,7 @@ def _compute_sample_range(history, parse_samples, start=None, verbose=False):
|
|||
return sample_range, current - start, current
|
||||
|
||||
|
||||
def history_bulk_data(parse_samples, start=None, verbose=False):
|
||||
def history_bulk_data(parse_samples, start=None, verbose=False, context=None):
|
||||
"""Fetch history data for a range of samples.
|
||||
|
||||
Args:
|
||||
|
|
@ -257,23 +748,31 @@ def history_bulk_data(parse_samples, start=None, verbose=False):
|
|||
function represents the counter value of the last data sample
|
||||
returned, so if that value is passed as start in a subsequent call
|
||||
to this function, only new samples will be returned.
|
||||
NOTE: The sample counter will reset to 0 when the dish reboots. If
|
||||
|
||||
Note: The sample counter will reset to 0 when the dish reboots. If
|
||||
the requested start value is greater than the new "end_counter"
|
||||
value, this function will assume that happened and treat all
|
||||
samples as being later than the requested start, and thus include
|
||||
them (bounded by parse_samples, if it is not -1).
|
||||
verbose (bool): Optionally produce verbose output.
|
||||
context (ChannelContext): Optionally provide a channel for reuse
|
||||
across repeated calls.
|
||||
|
||||
Returns:
|
||||
A tuple with 2 dicts, the first mapping general data names to their
|
||||
values and the second mapping bulk history data names to their values.
|
||||
|
||||
Note: The field names in the returned data do _not_ include brackets
|
||||
to indicate sequences, since those would just need to be parsed
|
||||
out. The general data is all single items and the bulk history
|
||||
data is all sequences.
|
||||
|
||||
Raises:
|
||||
GrpcError: Failed getting history info from the Starlink user
|
||||
terminal.
|
||||
"""
|
||||
try:
|
||||
history = get_history()
|
||||
history = get_history(context)
|
||||
except grpc.RpcError as e:
|
||||
raise GrpcError(e)
|
||||
|
||||
|
|
@ -314,25 +813,41 @@ def history_bulk_data(parse_samples, start=None, verbose=False):
|
|||
}
|
||||
|
||||
|
||||
def history_ping_stats(parse_samples, verbose=False):
|
||||
def history_ping_stats(parse_samples, verbose=False, context=None):
|
||||
"""Deprecated. Use history_stats instead."""
|
||||
return history_stats(parse_samples, verbose=verbose, context=context)[0:3]
|
||||
|
||||
|
||||
def history_stats(parse_samples, verbose=False, context=None):
|
||||
"""Fetch, parse, and compute the packet loss stats.
|
||||
|
||||
Note:
|
||||
See module level docs regarding brackets in field names.
|
||||
|
||||
Args:
|
||||
parse_samples (int): Number of samples to process, or -1 to parse all
|
||||
available samples.
|
||||
verbose (bool): Optionally produce verbose output.
|
||||
context (ChannelContext): Optionally provide a channel for reuse
|
||||
across repeated calls.
|
||||
|
||||
Returns:
|
||||
A tuple with 3 dicts, the first mapping general data names to their
|
||||
values, the second mapping ping drop stat names to their values and
|
||||
the third mapping ping drop run length stat names to their values.
|
||||
A tuple with 6 dicts, mapping general data names, ping drop stat
|
||||
names, ping drop run length stat names, ping latency stat names,
|
||||
loaded ping latency stat names, and bandwidth usage stat names to
|
||||
their respective values, in that order.
|
||||
|
||||
Note:
|
||||
Additional dicts may be added to this tuple in the future with
|
||||
additional data groups, so it not recommended for the caller to
|
||||
assume exactly 6 elements.
|
||||
|
||||
Raises:
|
||||
GrpcError: Failed getting history info from the Starlink user
|
||||
terminal.
|
||||
"""
|
||||
try:
|
||||
history = get_history()
|
||||
history = get_history(context)
|
||||
except grpc.RpcError as e:
|
||||
raise GrpcError(e)
|
||||
|
||||
|
|
@ -354,6 +869,13 @@ def history_ping_stats(parse_samples, verbose=False):
|
|||
run_length = 0
|
||||
init_run_length = None
|
||||
|
||||
usage_down = 0.0
|
||||
usage_up = 0.0
|
||||
|
||||
rtt_full = []
|
||||
rtt_all = []
|
||||
rtt_buckets = [[] for _ in range(15)]
|
||||
|
||||
for i in sample_range:
|
||||
d = history.pop_ping_drop_rate[i]
|
||||
if d >= 1:
|
||||
|
|
@ -387,6 +909,22 @@ def history_ping_stats(parse_samples, verbose=False):
|
|||
count_full_obstruct += 1
|
||||
tot += d
|
||||
|
||||
down = history.downlink_throughput_bps[i]
|
||||
usage_down += down
|
||||
up = history.uplink_throughput_bps[i]
|
||||
usage_up += up
|
||||
|
||||
rtt = history.pop_ping_latency_ms[i]
|
||||
# note that "full" here means the opposite of ping drop full
|
||||
if d == 0.0:
|
||||
rtt_full.append(rtt)
|
||||
if down + up > 500000:
|
||||
rtt_buckets[min(14, int(math.log2((down+up) / 500000)))].append(rtt)
|
||||
else:
|
||||
rtt_buckets[0].append(rtt)
|
||||
if d < 1.0:
|
||||
rtt_all.append((rtt, 1.0 - d))
|
||||
|
||||
# If the entire sample set is one big drop run, it will be both initial
|
||||
# fragment (continued from prior sample range) and final one (continued
|
||||
# to next sample range), but to avoid double-reporting, just call it
|
||||
|
|
@ -395,6 +933,53 @@ def history_ping_stats(parse_samples, verbose=False):
|
|||
init_run_length = run_length
|
||||
run_length = 0
|
||||
|
||||
def weighted_mean_and_quantiles(data, n):
|
||||
if not data:
|
||||
return None, [None] * (n+1)
|
||||
total_weight = sum(x[1] for x in data)
|
||||
result = []
|
||||
items = iter(data)
|
||||
value, accum_weight = next(items)
|
||||
accum_value = value * accum_weight
|
||||
for boundary in (total_weight * x / n for x in range(n)):
|
||||
while accum_weight < boundary:
|
||||
try:
|
||||
value, weight = next(items)
|
||||
accum_value += value * weight
|
||||
accum_weight += weight
|
||||
except StopIteration:
|
||||
# shouldn't happen, but in case of float precision weirdness...
|
||||
break
|
||||
result.append(value)
|
||||
result.append(data[-1][0])
|
||||
accum_value += sum(x[0] for x in items)
|
||||
return accum_value / total_weight, result
|
||||
|
||||
bucket_samples = []
|
||||
bucket_min = []
|
||||
bucket_median = []
|
||||
bucket_max = []
|
||||
for bucket in rtt_buckets:
|
||||
if bucket:
|
||||
bucket_samples.append(len(bucket))
|
||||
bucket_min.append(min(bucket))
|
||||
bucket_median.append(statistics.median(bucket))
|
||||
bucket_max.append(max(bucket))
|
||||
else:
|
||||
bucket_samples.append(0)
|
||||
bucket_min.append(None)
|
||||
bucket_median.append(None)
|
||||
bucket_max.append(None)
|
||||
|
||||
rtt_all.sort(key=lambda x: x[0])
|
||||
wmean_all, wdeciles_all = weighted_mean_and_quantiles(rtt_all, 10)
|
||||
if rtt_full:
|
||||
deciles_full = [min(rtt_full)]
|
||||
deciles_full.extend(statistics.quantiles(rtt_full, n=10, method="inclusive"))
|
||||
deciles_full.append(max(rtt_full))
|
||||
else:
|
||||
deciles_full = [None] * 11
|
||||
|
||||
return {
|
||||
"samples": parse_samples,
|
||||
"end_counter": current,
|
||||
|
|
@ -410,6 +995,20 @@ def history_ping_stats(parse_samples, verbose=False):
|
|||
}, {
|
||||
"init_run_fragment": init_run_length,
|
||||
"final_run_fragment": run_length,
|
||||
"run_seconds": second_runs,
|
||||
"run_minutes": minute_runs,
|
||||
"run_seconds[1,]": second_runs,
|
||||
"run_minutes[1,]": minute_runs,
|
||||
}, {
|
||||
"mean_all_ping_latency": wmean_all,
|
||||
"deciles_all_ping_latency[]": wdeciles_all,
|
||||
"mean_full_ping_latency": statistics.fmean(rtt_full) if rtt_full else None,
|
||||
"deciles_full_ping_latency[]": deciles_full,
|
||||
"stdev_full_ping_latency": statistics.pstdev(rtt_full) if rtt_full else None,
|
||||
}, {
|
||||
"load_bucket_samples[]": bucket_samples,
|
||||
"load_bucket_min_latency[]": bucket_min,
|
||||
"load_bucket_median_latency[]": bucket_median,
|
||||
"load_bucket_max_latency[]": bucket_max,
|
||||
}, {
|
||||
"download_usage": int(round(usage_down / 8)),
|
||||
"upload_usage": int(round(usage_up / 8)),
|
||||
}
|
||||
|
|
|
|||
Loading…
Reference in a new issue